Appendix B — Data Wrangling: Data Sources
C Datasources that provide CSV or Excel
C.1 Government data
C.3 General Sources
CORGIS: The Collection of Really Great, Interesting, Situated Datasets. Former student says, “They do a good job of explaining what’s in each dataset and what it means.”
Data is plural newsletter An eclectic source of data sets with a fun newsletter.
Reddit’s Data is Beautiful Fun vizualizations and links to data sources.
Data-dot-world Lots of great datasets and can also host your own data and project (figures etc.) Data.world is also interesting because it’s a startup here in Austin and they have jobs from time to time (and strong iSchool connections).
Kaggle. But please try to trace back to original datasets to confirm they come from different organizations and they haven’t been cleaned up.
C.4 Reality TV shows
- (From Data Is Plural At TaskMaster.Info, Karl Craven is “obsessively documenting the international Taskmaster franchise,” which began as a British game show on which comedians compete to win challenges such as watermelon speed-eating and high-fiving strangers. Reddit user Alohamori has used the site and other sources to create a “ridiculously comprehensive” database of that information, enabling queries such as the fastest-completed tasks, tasks awarding zero points, and episodes ending in ties. Bonus link: Taskmaster’s official YouTube channel.
C.5 Articles about finding datasources
- https://blog.google/products/search/discovering-millions-datasets-web/
C.6 Recent news articles with datasets that might make for useful projects
- TXDOT just released their response to the I35 expansion public comments. There is a PDF table with tags and responses that could be extracted and analyzed: https://my35capex.com/wp-content/uploads/2023/08/APPROVED-FEIS-ROD_Appendix-G-Comment-Response-Matrix-from-Public-Hearing-Notice-of-Availability-of-DEIS_2023-08-14.pdf
D Other data sources:
HTML tables are relatively easy to convert to csv using online tools. ConvertCSV has been useful for students (although be conscious that you have to choose the right table on the page):
Wikipedia tables can provide useful data. There are a range of tools that can convert them. Students have used http://wikitable2csv.ggor.de/ and http://import.io. Another option is the wikidata project which provides CSV downloads of InfoBoxes (and perhaps other things).
PDF files can provide useful data, especially from tables, but they have to be converted. The conversion tool that I like the best is http://tabula.technology/
Websites with data in structured formats other than tables can be extracted through “scraping” but that is out the course scope. Students have had luck with http://import.io to set up scraping.
E Data that can be hard to use:
Examples of data that are harder to deal with:
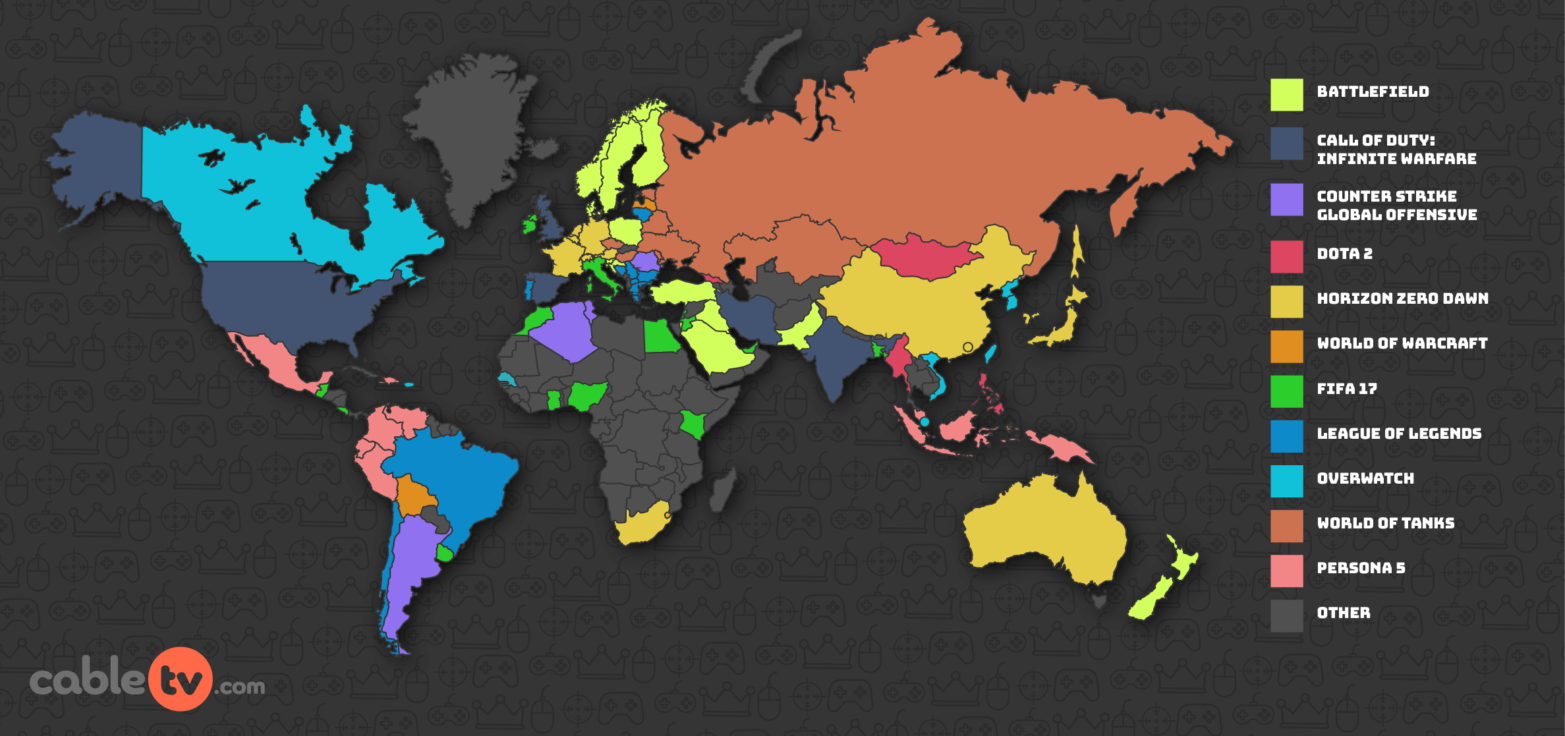
Images of plots (very, very hard, I’ve heard of people doing this but I never have). e.g., Video Game Popularity plot, no underlying data download.
“Record format” (requires a sophisticated scraper). e.g., Dog Breed Personalities
Sort of a combo of record format and images. e.g., A menu archive
Proprietary formats (requires an importer).e.g, https://dataverse.harvard.edu/file.xhtml?persistentId=doi:10.7910/DVN/6QWX7Q/X1EKIG&version=2.0
Nested headers (and merged cells) (can be dealt with, common in Census data). Data in PDFs (try tabula.technology) https://www.cdc.gov/nchs/data/nvsr/nvsr68/nvsr68_13_tables-508.pdf (Also a PDF, see above).
Non-rectangular tabular data: https://www.nps.gov/aboutus/visitation-numbers.htm (bottom table). We can deal with this using Python, although there are some challenges.
Sort of a mix of lots of types: https://www.daytranslations.com/blog/popular-video-games-continent/
{kind=link}