10 Aliases
We can rename columns in our results table using the AS keyword. In this way we are not limited to directly copying the names of the columns from the tables. For example, when we select just the ‘red’ objects we can rename the column in the results to reflect that:
SELECT *
FROM colors
JOIN objects
ON colors.id = objects.color_id
WHERE color.name = 'red'
SELECT objects.name AS 'name_of_red_objects'
FROM colors
JOIN objects
ON colors.id = objects.color_id
WHERE color.name = 'red'It is good practice to follow the same conventions one would in naming columns: using lowercase and connecting words with underscores. This is because results are very often further processed by computer tools (and therefore spaces can be a problem).
10.1 Aggregate Functions
Thus far we’ve learned how to narrow down rows and columns to obtain answers to queries. We’ve narrowed down rows using conditions (WHERE/JOIN/LIMIT), and columns using SELECT.
In this module we’re going to learn how to work with columns of data. Aggregate functions ‘collapse’ the values in a column, returning a result. The functions go into the SELECT part.
One of the simplest is to add together all the of the values using SUM. This figure shows part of the tickets table from our class_music_festival database.
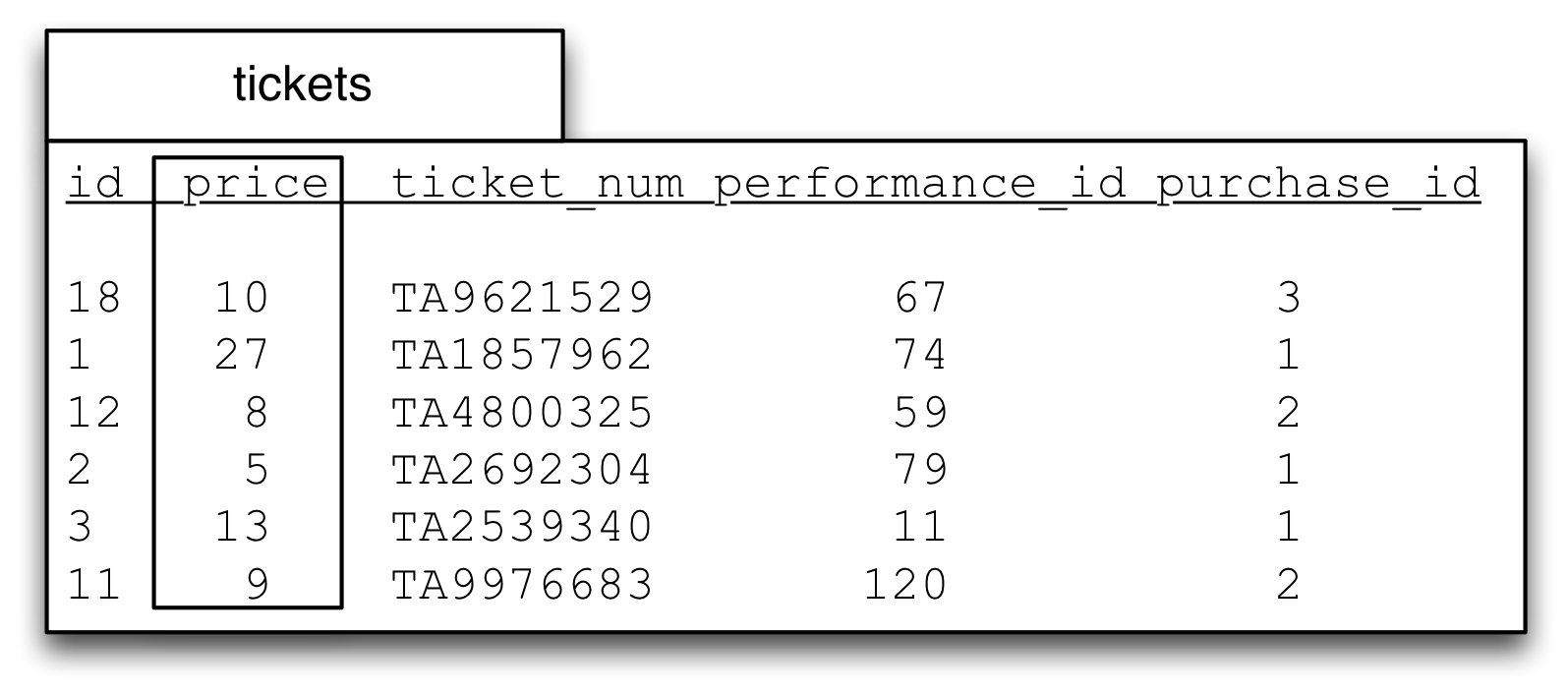
If we wanted to know the total of the values in the tickets.price column we can get that with the three steps below.
-- identify the rows we want to work with
SELECT *
FROM 'tickets.csv'
-- identify just the column we want to work with
SELECT tickets.price
FROM 'tickets.csv'
-- Collapse the column vertically to a single value.
SELECT SUM(tickets.price)
FROM 'tickets.csv'Which would give us a result of
72 (1 row)When we use an aggregate function it is convenient to employ an alias to give a name to the result:
SELECT SUM(tickets.price) AS total_of_tickets_price
FROM 'tickets.csv'There are a set of these functions that we can apply: SUM for addition,AVG for the average of the numbers in the column. There are also the MIN for minimum, MAX for maximum, but be wary of those (more on that below).
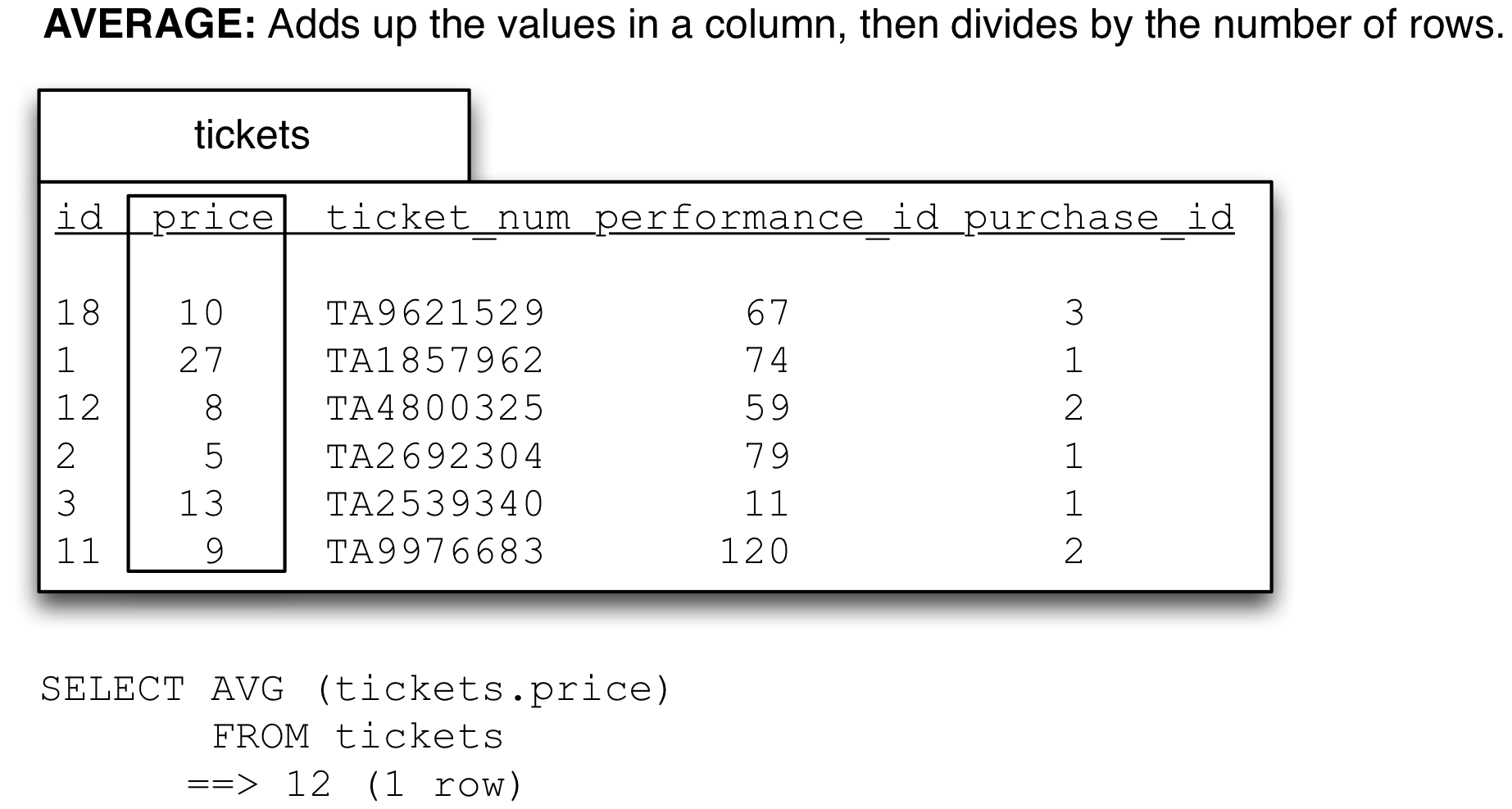
Note that there is no MEDIAN function nor a MODE function in sql. Both can be done but it is complicated and once one is doing real statistics it is better to move out of SQL and use python (or R).
10.2 DISTINCT
Another useful function is DISTINCT which reduces the column by removing duplicates. Unlike other aggregation functions DISTINCT does not use parens.
-- Who made purchases of tickets? People might have purchased twice
-- but only show their name once.
-- Start with purchases to be sure that the person made a purchase.
-- This table has one row per purchase.
SELECT *
FROM purchases
-- Join to people to get names
SELECT *
FROM purchases
JOIN people
ON purchases.person_id = people.id
-- We still have a row per purchase, so if someone made more
-- than one they'd show up twice.
SELECT people.name
FROM purchases
JOIN people
ON purchases.person_id = people.id
-- remove possible duplicates
SELECT DISTINCT people.name
FROM purchases
JOIN people
ON purchases.person_id = people.id10.3 COUNT (three forms of COUNT)
Counting values in a column (or rows in a table) is an important form of aggregation function. At first you might not think of that as aggregating, but it does take a column (or a table) and reduce it down to a single value, just as functions like SUM or AVG do.
There are three forms of COUNT, each subtly different from each other.
The three forms of COUNT are: 1. COUNT(*) counts the number of rows. 2. COUNT(column) counts the number of non-NULL values in a column. 3. COUNT(DISTINCT column) counts the unique values in a column, after removing NULLs.
COUNT(*) can be useful for simple tables:
SELECT *
FROM 'tickets.csv'
SELECT COUNT(*) AS count_of_tickets
FROM 'tickets.csv'Or used with data conditions to count the number of things that meet some condition, such as how many bands had fees higher than $100?
SELECT *
FROM 'bands.csv'
SELECT *
FROM 'bands.csv'
WHERE bands.fee > 100
SELECT COUNT(*) as number_of_expensive_bands
FROM 'bands.csv'
WHERE bands.fee > 100You almost always want to use an AS alias with COUNT(*).
COUNT(*) is also useful after joins. For example, one can find the number of performances at the ‘Austin Kiddie Limits presented by H-E-B’ venue:
SELECT *
FROM venues
-- find just the venue.
SELECT *
FROM venues
WHERE venues.name = 'Austin Kiddie Limits presented by H-E-B'
-- join over to performances. Returns a row for each
-- performance at 'Austin Kiddie Limits presented by H-E-B'.
SELECT *
FROM venues
JOIN performances
ON venues.id = performances.venue_id
WHERE venues.name = 'Austin Kiddie Limits presented by H-E-B'
SELECT COUNT(*) AS number_performances_at_kiddie
FROM venues
JOIN performances
ON venues.id = performances.venue_id
WHERE venues.name = 'Austin Kiddie Limits presented by H-E-B'And we can see that there were 16 performances at ‘Austin Kiddie Limits presented by H-E-B’ venue.
COUNT(DISTINCT column) is also very useful. For example, counting the number of bands that play at the Austin Kiddie Limits presented by H-E-B’ venue. As above you have to join to performances to ensure that a performance took place, but given that bands might play more than one performance you could end up with more than one row for each band. DISTINCT helps resolve that.
-- following on from above. This has one row per performance.
SELECT *
FROM venues
JOIN performances
ON venues.id = performances.venue_id
WHERE venues.name = 'Austin Kiddie Limits presented by H-E-B'
--- performances has a field about the bands, band_id.
-- If the id of a band appears in band_id then they played at BMI, but
-- if they played more than once their id would show up more than once.
-- We can resolve that using COUNT DISTINCT
SELECT COUNT(DISTINCT performances.band_id)
FROM venues
JOIN performances
ON venues.id = performances.venue_id
WHERE venues.name = 'Austin Kiddie Limits presented by H-E-B'
-- Note that even though the question was about bands, we didn't need
-- to join the bands table, since performances.band_id is about bands.Generally speaking counting rows or distinct ids is a better approach than counting distinct names because many things in the world can have the same name (as the Office Space movie, filmed in Austin, showed us memorably about ‘Michael Bolton’.)
To reiterate, consider the differences between the three forms of COUNT on this list:
id, name
--------
1, Domhog
2, NULL
3, Domhog
4, ShuyenCOUNT(*)would give the answer4(there are 4 rows).COUNT(DISTINCT name)would give the answer2(just ‘Domhog’ and ‘Shuyen’)COUNT(name)would give the answer3(there are 3 non-null values in the name column.)
I advise people to avoid COUNT(column) because I find the semantics confusing in a query. I mean that what people are intending to accomplish is unclear. More, though, I haven’t come across a time when it is necessary.
Whenever you are tempted to use COUNT(column), ask yourself whether COUNT(*) is clearer and what you actually mean. Most counting queries are questions about the number of rows (after some conditions/joins), not the number of non-NULL values.
ps. I’m very interested to find an example where COUNT(column) is the ideal thing, so please email me if you see one. Only thing I can think of is something like counting records with relationships. e.g. a table like people(id, name, sig_other_id) where those not in a relationship have NULL for their sig_other_id.
--How many people have sig others?
SELECT COUNT(sig_other_id)
FROM peopleBut I think even that would be much clearer as:
SELECT COUNT(*) as sig_other_count
FROM people
WHERE people.sig_other_id IS NOT NULL10.4 A note about MIN and MAX vs ORDER BY LIMIT 1
The aggregate functions MIN() and MAX() seem straight forward, the find the minimum or maximum value in a column.

SELECT MIN(tickets.price) AS lowest_ticket_price
FROM 'tickets.csv'Which will, correctly, return 5, the lowest value in the table.
However questions about the ‘lowest’, ‘highest’, ‘earliest’ usually also want another part of the row with that value. e.g., ‘Who bought the earliest ticket?’, ‘which ticket number had the lowest price?’
These queries are better answered using ORDER BY and LIMIT 1. Using MIN and MAX the intuitive way will silently give a totally incorrect answer.
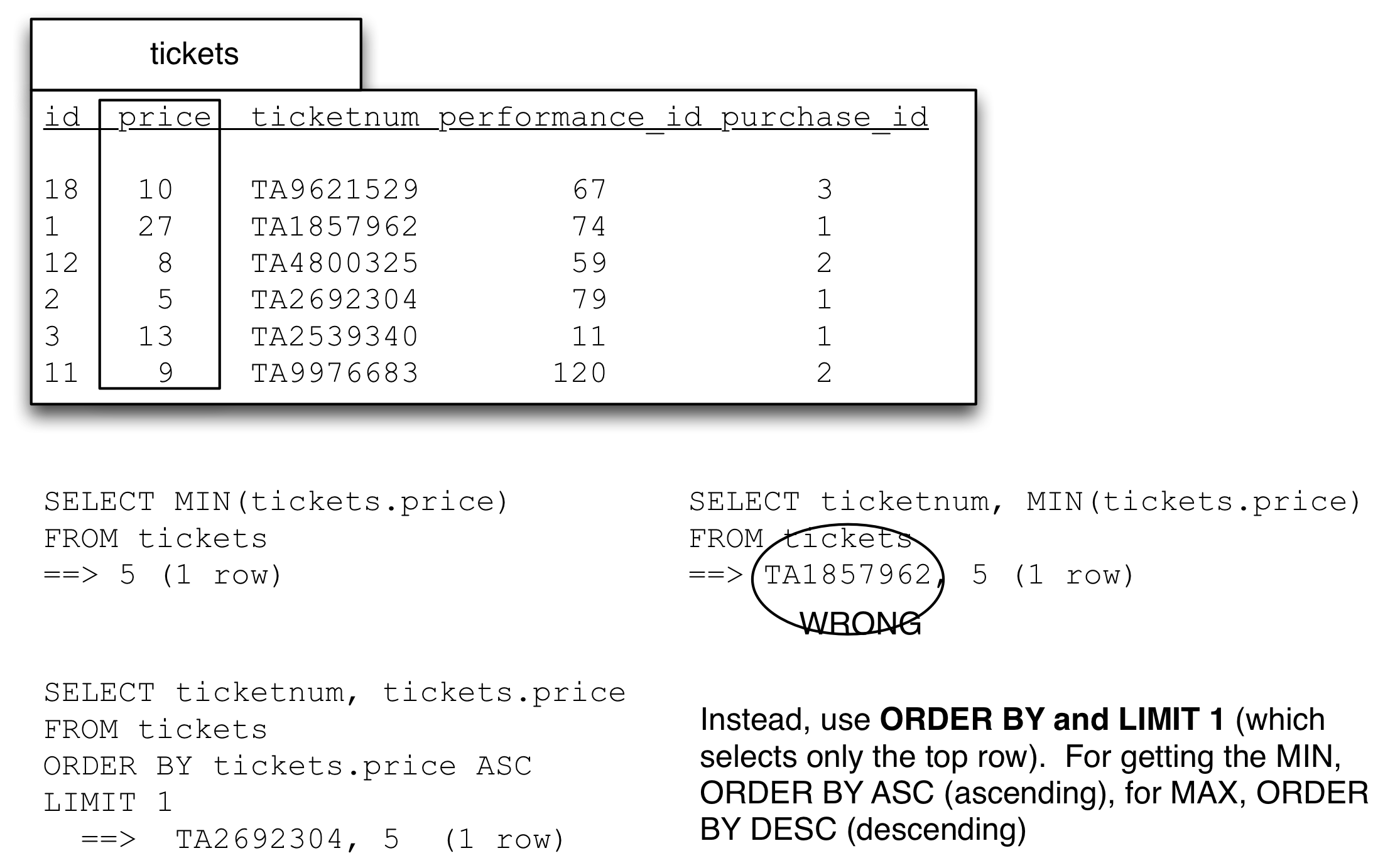
This bears repeating: If you use MIN or MAX in the SELECT clause with any other column you will not get the value in the row that had the lowest value, you will get a random value from the other column. I know that this is hard to believe. We’ll talk about why when we get to groups.
While you should use ORDER BY and LIMIT 1, you can use MIN or MAX but you have to use it via IN (or a sub-query). Here think of the question as two steps: ‘What is the minimum price? And what the ticketnumbers and prices for those tickets which had that price?’
-- First get the minimum value
SELECT MIN(tickets.price) FROM 'tickets.csv'
-- That returns a single value which you then can use.
-- You get the server to 'remember' it by surrounding the query with parens.
SELECT tickets.ticketnum, tickets.price
FROM 'tickets.csv'
WHERE tickets.price = (SELECT MIN(tickets.price) FROM 'tickets.csv')But hey if you use ORDER BY and LIMIT you can easily get the top five or bottom whatever (as long as ties don’t matter), so just don’t use MIN or MAX in the SELECT clause, unless it’s a sub-query.
SELECT tickets.ticketnum, tickets.price
FROM 'tickets.csv'
ORDER BY tickets.price ASC
LIMIT 5I would only use MIN or MAX when ties really matter, and only in a sub-query. Even then there is a more direct approach to ranking (both in SQL and in data frame processing libraries like pandas and tidyverse).
10.5 Exercises:
Do the five exercises on SUM and COUNT on SQLZoo