14 CSV to SQL INSERT
For our projects we have two different representation formats for our data.
The first is the CSV files you found on the web. The second is the database you have designed.
You will notice that there is not a direct match between the format of the data in the CSV files and the tables in the database.
For example, consider our Student-Enrollment-Course database:
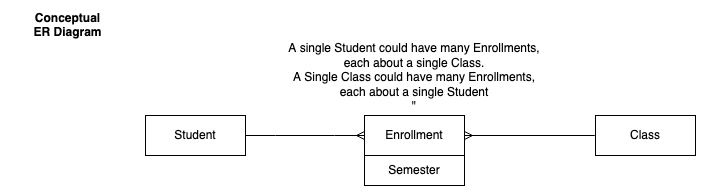
And that translates to three tables
students(id, name)
classes(id, name)
enrollments(id, semester, student_id, class_id)But you may receive CSV data that represents that data in many different forms.
For example, it might look like:
class_name, student_name, semester
Divination, Hermione, Fall
Divination, Harry, Fall
Potions, Ron, SpringOr you might get a file where each row is a list of students in that course.
course_name, semester, student_list
Divination, Fall, Hermione, Harry
Potions, Spring, RonOr you might get a file per class
Divination_Fall.csv
------------
name
Hermione
HarryPotions_Spring.csv
-----------
name
RonOr you might get a file per semester or a file per student.
You get the idea! The same data can be represented in many different forms. Generally we call these different forms “schemas”. Sometimes these are called different “record formats”, as in the classic 1989 paper by Bill Kent, The many forms of a single Fact, or Have you heard the one about the traveling salesman?.
Knowing that something is in a csv tells you nothing about the schema. csv is just a file format. schema is about how the data is organized within the file, what combination of columns, rows, and even data within the rows, has been used to hold the data.
Also note that Oracle and Postgres (specific SQL databases) confused this language by referring to different datastores on the server as schemas (when everyone else calls those different databases on the same server).
Changing between these different representations—these different schemas—is part of the transform part of the process called ETL: Extract, Transform, Load. Sometimes that process is called Data Mapping or Schema Transformation.
Regardless of the language diversity here, those working with data have a strong understanding of these transformations, within the overall process of Data Integration, and when combined with cleaning the data, this is all somewhat informally known as Data Wrangling.
Phew.
14.1 From CSV to Database via SQL INSERT queries
In this course we will learn how to do these data transformations by reading a CSV file, then executing SQL INSERT queries to put the data into our database. As we do this we will changing the schema of the data as needed and create primary keys (id) as needed, which we will then use as foreign keys where needed.
For example (and examples are key to making this clear), lets think of the sequence of SQL queries needed to move data from this single csv:
students_classes.csv
------------
class_name, student_name, semester
Divination, Hermione, Fall
Divination, Harry, Fall
Potions, Ron, Springinto these tables:
students(id, name)
------------------
classes(id, name)
-----------------
enrollments(id, semester, student_id, class_id)
-----------------------------------------------Looking at the data, we can map it in our head, noticing that the structure of the csv file is similar to the structure of the enrollments table. For each row in student_classes.csv we will need to make one INSERT. It will need to be something like this:
INSERT INTO enrollments(id, semester, student_id, class_id)
VALUES (1, "Fall", "Hermione", "Divination");Yet it can’t be that exactly … because we have names for students and for courses, but we need ids. e.g., we have “Hermione” but we need 1 for the student_id column and we have “Divination” and we need 1 for the class_id column.
In fact eventually we want the tables to look like this:
students(id, name)
------------------
1, Hermione
2, Harry
3, Ron
classes(id, name)
-----------------
1, Divination
2, Potions
enrollments(id, semester, student_id, class_id)
-----------------------------------------------
1, Fall, 1, 1 # Hermine, Divination
2, Fall, 3, 1 # Ron, Divination
3, Spring, 2, 2, # Harry, PotionsSo our first challenge is to convert the string “Hermione” into the appropriate students.id primary key. There are two cases to consider.
- “Hermione” is already in the
studentstable. - “Hermione” is not in the
studentstable yet at all.
In the first case, we can use a straight-forward SELECT query to get the students.id for “Hermione”:
SELECT id
FROM students
WHERE name = 'Hermione'In the second case, we can do an INSERT query to create the new record and set it up so that it can create the id for us. We can also ask the database to get back the id that it created and assigned.
INSERT INTO students(name) VALUES ('Hermione') RETURNING idFor this to work we have to tell the database that we want it to automatically create unique id. Each specific database server does this in a different way.
For the table creation code to work you have to start your workbook with:
!pip install jupysql --quiet
!pip install duckdb-engine --quiet
import duckdb
%reload_ext sql
%config SqlMagic.autopandas = True
%config SqlMagic.feedback = False
%config SqlMagic.displaycon = False
%sql duckdb:///duckdb-file.dbAnd remember to run the SQL in python cells that start with %%sql
For DuckDB we have to create a sequence and tell it to use that sequence as the default primary key, as shown in the tip below.
-- drop if they exist
DROP TABLE IF EXISTS students;
DROP SEQUENCE IF EXISTS seq_student_id;
-- create sequence then use it as default
CREATE SEQUENCE seq_student_id START 1;
CREATE TABLE students (
id INT PRIMARY KEY DEFAULT NEXTVAL('seq_student_id'),
name TEXT
);
DROP TABLE IF EXISTS classes;
DROP SEQUENCE IF EXISTS seq_class_id;
-- create sequence then use it as default
CREATE SEQUENCE seq_class_id START 1;
CREATE TABLE classes (
id INT PRIMARY KEY DEFAULT NEXTVAL('seq_class_id'),
name TEXT
);
DROP TABLE IF EXISTS enrollments;
DROP SEQUENCE IF EXISTS seq_enrollment_id;
-- create sequence then use it as default
CREATE SEQUENCE seq_enrollment_id START 1;
CREATE TABLE enrollments (
id INT PRIMARY KEY DEFAULT NEXTVAL('seq_student_id'),
semester TEXT,
student_id INT,
class_id INT,
);14.2 Sequence of SQL needed
Thus we first check if Hermione exists, then create her row if needed.
SELECT id FROM students WHERE name = 'Hermione';
-- returns zero rows, therefore need to create.
INSERT INTO students(name) VALUES ('Hermione') RETURNING idWe can then do the same thing for the class:
SELECT id FROM classes WHERE name = 'Divination';
-- returns zero rows, therefore need to create.
INSERT INTO classes(name) VALUES ('Divination') RETURNING id;And now, either way, we have both the class_id and the student_id needed. We can now use INSERT to create the needed row in enrollments (the id for this row is auto created but we don’t need to use it so no RETURNING:
INSERT INTO enrollments(semester, student_id, class_id)
VALUES ('Fall', 1, 1)At the moment we have to copy these ids manually into the INSERT. Eventually we will use something very similar to str.format or f-strings.