12 Iterative Development, Regression Tests, and Continuous Integration
The coordination of work in open source is assisted by three practices: iterative development, regression tests, and continuous integration.
Iterative development has at its core the idea that the best way to know what to build is to get a product into a users hands quickly, collect feedback, then iterate.
Test suites allow a programming group to define expected behaviors and verify them using software tests. Then, when changes are introduced to the codebase, the test suite can show that the changes have not accidentally altered the expected behaviors.
Continuous Integration encourages frequent merging of developing code, running the test suite to ensure that nothing is merged to main unless all the tests pass.
12.1 Iterative Development
In software engineering, iterative development is contrasted with “the waterfall model”. Whereas “waterfall” is understood as a rigid structure of software planning and execution where each phase is complete and validated before moving to the next phase. Usually these phases involve at least Requirements, Design, Implementation, Deployment, Maintenance. The core idea is to be efficient and effective by knowing what should be built, having a careful and validated design, then write code optimized to that design, before rolling out a complete product that can be maintained at lower cost. Further reading: https://www.techtarget.com/searchsoftwarequality/definition/waterfall-model
In contrast, Iterative development expects many short repeated cycles of build, release, feedback, and redesign. A team doing iterative development seeks to quickly produce working software and get it in front of potential users. A core idea here is that it is hard for potential users to describe their requirements in the abstract, but it is easier for them to give feedback when they have something “in their hands”. This is because people think more clearly when their bodies are involved (an idea called “embodied cognition”) or at least real things like actual documents or real data in a database, more closely approximating the situation in which they would be using the software (an idea called “situated cognition).
There are many useful comparisons of agile and iterative development, including the Medium article that contains this figure.
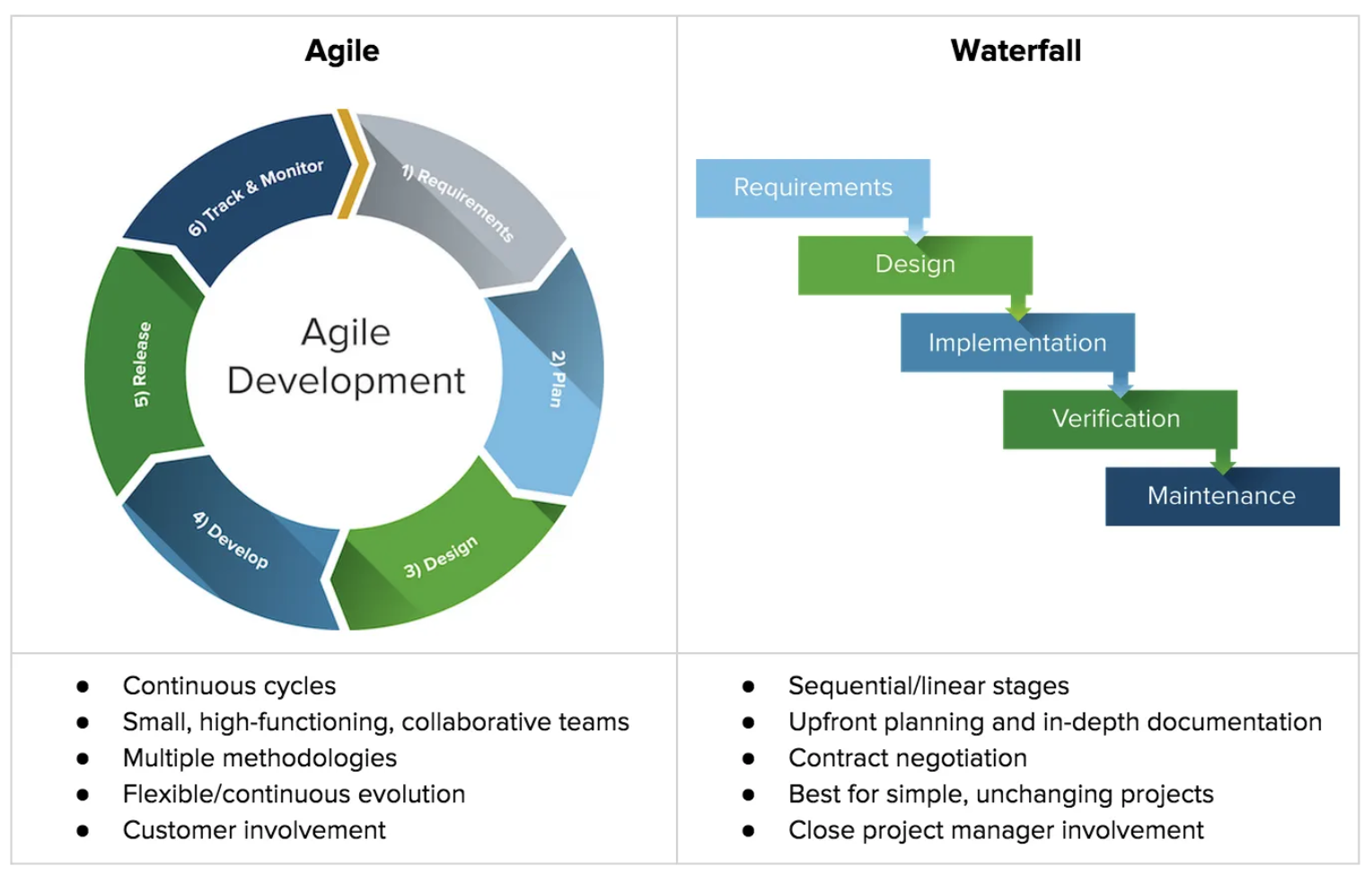
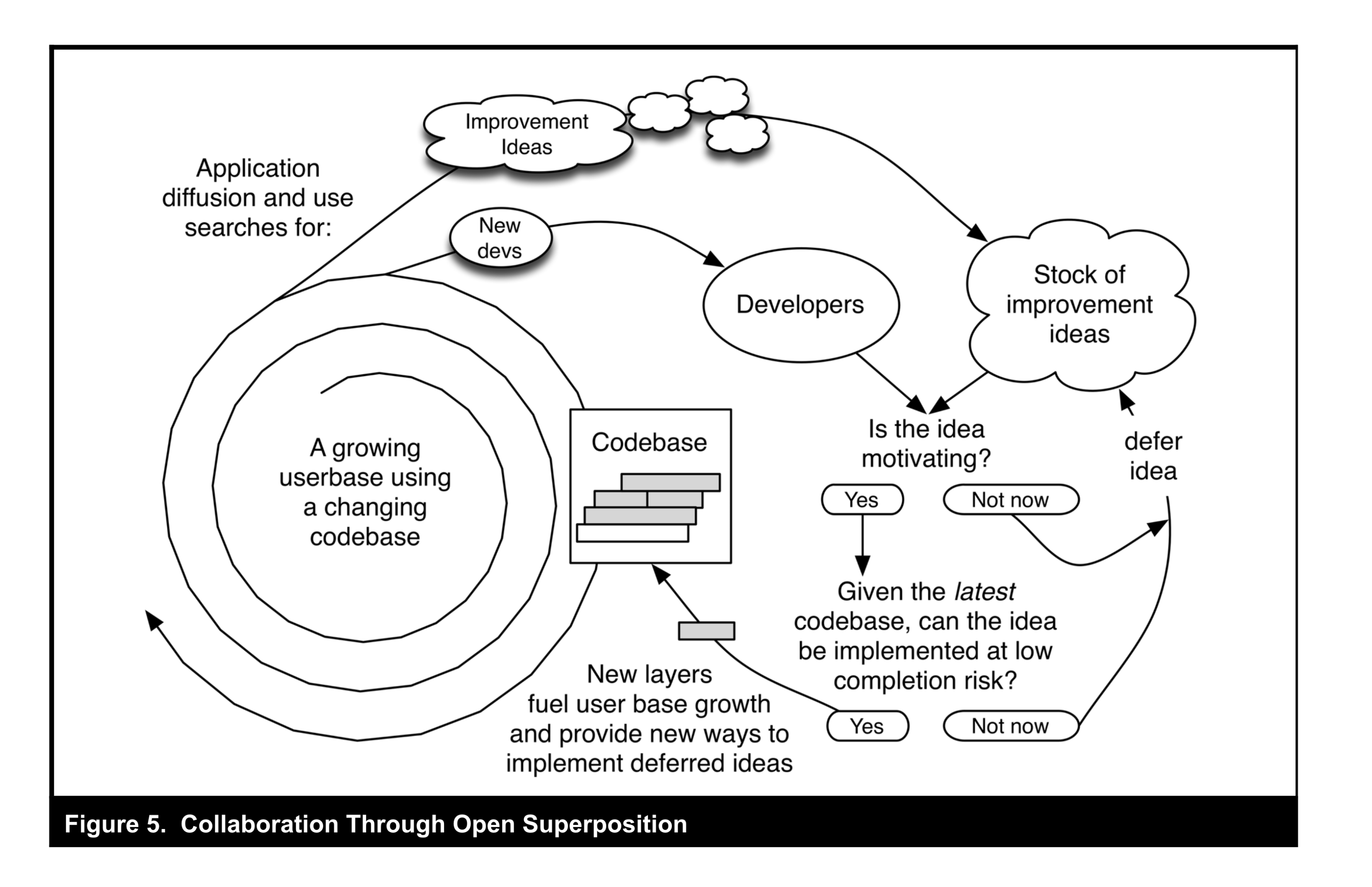
Iterative development plays a key role in open source. Open source projects typically do not undertake user research, but instead build things that work for the core developers. Those products then find their way into users hands. Users working directly with existing software then conceptualize improvements or identify flaws, some users then take the time to give feedback through Issues or bug reports, creating new ideas for developers to potentially implement.
Iterative development is part of what has become known as “Agile methods” and “Scrum” but those are more elaborate approaches to managing software development which are appropriate for companies and teams with employees. Further insights on this can be found in training materials about “Scrum” and “Kanban”. For example Atlassian (a software process and tooling company) provides materials here: https://www.atlassian.com/agile/kanban
Other useful readings include:
https://en.wikipedia.org/wiki/Iterative_and_incremental_development
Lest you think these are only fairly recent concepts, the idea of iteration as a way to manage uncertainty stems back at least to the early 1980s. See
Giddings, R. V. (1984). Accommodating Uncertainty in Software Design. Commun. ACM, 27(5), 428–434.”, https://doi.org/10.1145/358189.358066
12.2 Test Suites
Yet iterative development means lots of change. Changes come from within the project (new contributions, bug fixes) but also from outside the project, including changes in dependencies. Dependency changes come not only from bug-fixes, but also from new features in dependencies which offer new opportunities but also require changes in the codebase. Change can also come from periodic “clean ups” or “refactoring” efforts to reduce duplication and make a codebase easier to work with.
As code builds up over time the original intentions of developers can become less clear. While documentation (separate written guides to the code) can help, there is little motivation to write documentation and keep it up to date.
Test suites offer the opportunity to record the expected behavior of software. A software test provides an expected output (or behavior), identifies the code which should provide that output, and provides a way to run the code (often together with known input), and to compare expected vs actual output.
Test suites can also include a sort of meta-test that examines which lines of code are run when all the tests are run, then reports “coverage” to show what proportion of code has actually been tests.
12.3 Continuous Integration
Our third concept is continuous integration. CI encourages frequent merging of developing code, running the test suite to ensure that nothing is merged to main unless all the tests pass.
In projects that use CI, when a developer is creating a PR, the system will, in the background, run the test suite and see if all tests pass. Depending on the project policies, the developer may be able to continue to create the PR if the tests are failing, or the project may require that all tests pass even before a PR is created.
In GitHub, CI is enabled by by Github Actions. You can think of these as scripts that are executed on GitHub servers, kicked off by events within the GitHub system. They are able to spin up virtual machines, install the code, dependencies, and run test suites.
https://docs.github.com/en/actions/automating-builds-and-tests/about-continuous-integration
Research has examined how effectively open projects are able to implement these ideas to drive improvements:
Vasilescu, B., Yu, Y., Wang, H., Devanbu, P., & Filkov, V. (2015). Quality and Productivity Outcomes Relating to Continuous Integration in GitHub. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering (pp. 805–816). New York, NY, USA: ACM. https://doi.org/10.1145/2786805.2786850