Worked example of data wrangling
Here is a worked example of some moderate data wrangling, taken from my own work.
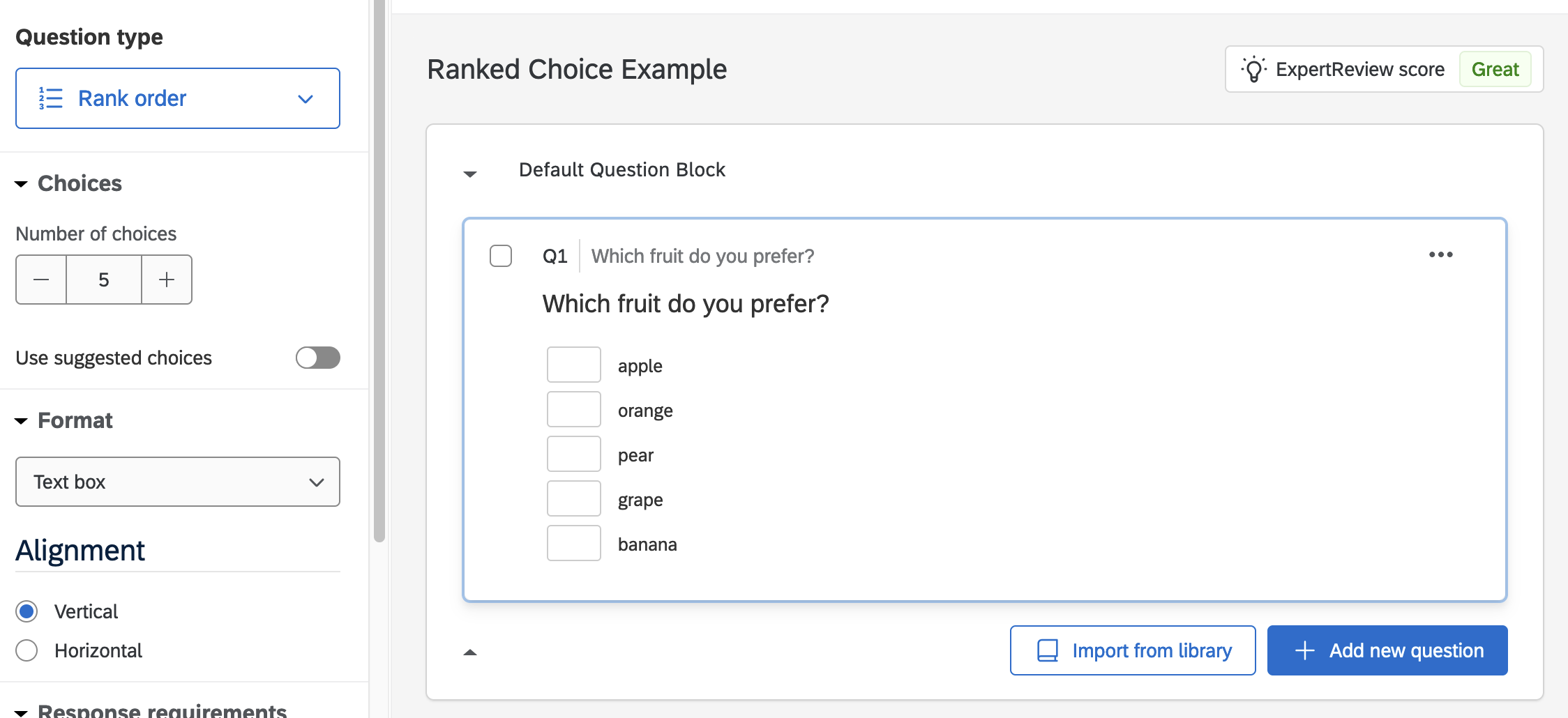
I created a survey using Qualtrics and included a ranked choice question. In qualtrics the question looks like this:
Eventually I want a dataframe that looks like this:
| response_id | fruit_in_order |
|---|---|
| response1 | apple, orange, pear, grape, banana |
| response2 | banana, grape, pear, orange, apple |
I filled out the survey three times, adding rankings between 1 and 5 for each fruit. I then downloaded a CSV export of the data (on the Data & Analysis tab) using these options (the radio button at the bottom did not seem to make a difference).
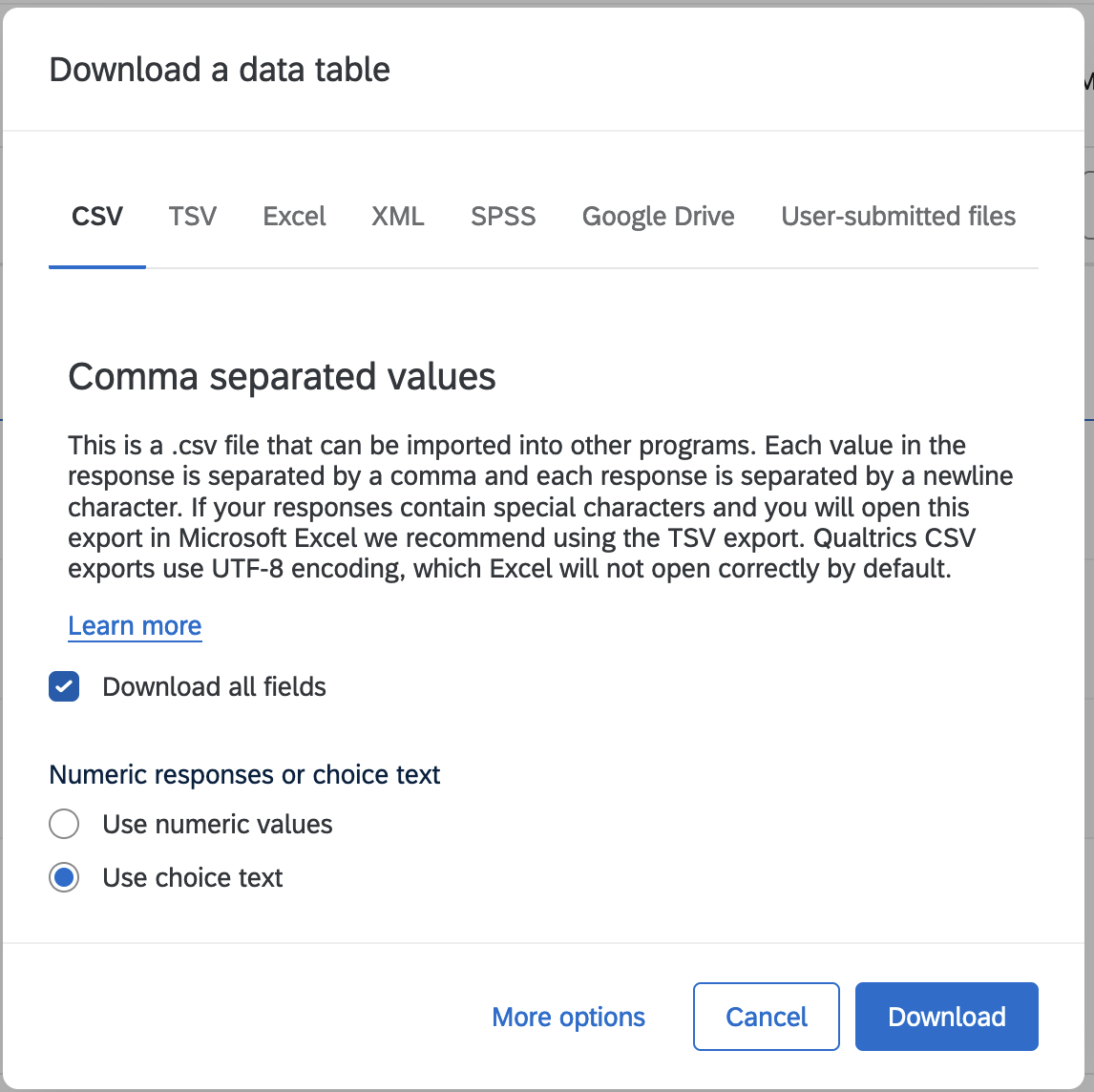
The downloaded file looks like this (scroll across to see all columns):
| StartDate | EndDate | Status | IPAddress | Progress | Duration (in seconds) | Finished | RecordedDate | ResponseId | RecipientLastName | RecipientFirstName | RecipientEmail | ExternalReference | LocationLatitude | LocationLongitude | DistributionChannel | UserLanguage | Q1_1 | Q1_2 | Q1_3 | Q1_4 | Q1_5 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Start Date | End Date | Response Type | IP Address | Progress | Duration (in seconds) | Finished | Recorded Date | Response ID | Recipient Last Name | Recipient First Name | Recipient Email | External Data Reference | Location Latitude | Location Longitude | Distribution Channel | User Language | Which fruit do you prefer? - apple | Which fruit do you prefer? - orange | Which fruit do you prefer? - pear | Which fruit do you prefer? - grape | Which fruit do you prefer? - banana |
| {"ImportId":"startDate","timeZone":"America/Chicago"} | {"ImportId":"endDate","timeZone":"America/Chicago"} | {"ImportId":"status"} | {"ImportId":"ipAddress"} | {"ImportId":"progress"} | {"ImportId":"duration"} | {"ImportId":"finished"} | {"ImportId":"recordedDate","timeZone":"America/Chicago"} | {"ImportId":"_recordId"} | {"ImportId":"recipientLastName"} | {"ImportId":"recipientFirstName"} | {"ImportId":"recipientEmail"} | {"ImportId":"externalDataReference"} | {"ImportId":"locationLatitude"} | {"ImportId":"locationLongitude"} | {"ImportId":"distributionChannel"} | {"ImportId":"userLanguage"} | {"ImportId":"QID1_1"} | {"ImportId":"QID1_2"} | {"ImportId":"QID1_3"} | {"ImportId":"QID1_4"} | {"ImportId":"QID1_5"} |
| 2024-09-10 04:53:09 | 2024-09-10 04:53:26 | IP Address | 77.241.226.16 | 100 | 16 | True | 2024-09-10 04:53:26 | R_2Gv45TBz2xAZBgw | NA | NA | NA | NA | 51.9172 | 4.5049 | anonymous | EN | 1 | 2 | 3 | 4 | 5 |
| 2024-09-10 04:53:29 | 2024-09-10 04:53:38 | IP Address | 77.241.226.16 | 100 | 9 | True | 2024-09-10 04:53:39 | R_2Dc4B4z51U9BbVu | NA | NA | NA | NA | 51.9172 | 4.5049 | anonymous | EN | 3 | 5 | 2 | 1 | 4 |
| 2024-09-10 04:53:42 | 2024-09-10 04:53:51 | IP Address | 77.241.226.16 | 100 | 8 | True | 2024-09-10 04:53:51 | R_2VjavSpNBqeI26l | NA | NA | NA | NA | 51.9172 | 4.5049 | anonymous | EN | 5 | 4 | 3 | 2 | 1 |
This is a curious file … there are lots of headers. Most of them are meta-data about the survey response. Let’s exclude columns until we can see the data a little more easily. Here I’m just showing the ResponseId and the columns that start with “Q” which hold the actual answers.
| ResponseId | Q1_1 | Q1_2 | Q1_3 | Q1_4 | Q1_5 |
|---|---|---|---|---|---|
| Response ID | Which fruit do you prefer? - apple | Which fruit do you prefer? - orange | Which fruit do you prefer? - pear | Which fruit do you prefer? - grape | Which fruit do you prefer? - banana |
| {"ImportId":"_recordId"} | {"ImportId":"QID1_1"} | {"ImportId":"QID1_2"} | {"ImportId":"QID1_3"} | {"ImportId":"QID1_4"} | {"ImportId":"QID1_5"} |
| R_2Gv45TBz2xAZBgw | 1 | 2 | 3 | 4 | 5 |
| R_2Dc4B4z51U9BbVu | 3 | 5 | 2 | 1 | 4 |
| R_2VjavSpNBqeI26l | 5 | 4 | 3 | 2 | 1 |
Now we can see that our five options have become Q1_1 through Q1_5. The numbers in those columns seem like they are the rankings that were typed into the text boxes. At least for the bottom three rows, which correspond to the actual survey responses.
The first two rows, though, are meta-data of some sort. The second row is some sort of export meta-data that we won’t need to use. I’ll drop that row to make this a bit clearer still.
| ResponseId | Q1_1 | Q1_2 | Q1_3 | Q1_4 | Q1_5 |
|---|---|---|---|---|---|
| Response ID | Which fruit do you prefer? - apple | Which fruit do you prefer? - orange | Which fruit do you prefer? - pear | Which fruit do you prefer? - grape | Which fruit do you prefer? - banana |
| R_2Gv45TBz2xAZBgw | 1 | 2 | 3 | 4 | 5 |
| R_2Dc4B4z51U9BbVu | 3 | 5 | 2 | 1 | 4 |
| R_2VjavSpNBqeI26l | 5 | 4 | 3 | 2 | 1 |
Now we can see that the first data row is still different than the others … looks like it holds the question text and then the actual label that was used. Since this is a different sort of data than the number responses, I’m going to split this into two tables. First I’ll exclude all the data rows (to get just the labels). Then I’ll exclude the labels row, to get just the data.
| Labels | |||||
|---|---|---|---|---|---|
| ResponseId | Q1_1 | Q1_2 | Q1_3 | Q1_4 | Q1_5 |
| Response ID | Which fruit do you prefer? - apple | Which fruit do you prefer? - orange | Which fruit do you prefer? - pear | Which fruit do you prefer? - grape | Which fruit do you prefer? - banana |
The first column isn’t relevant here, so we will exclude that. Then this is starting to look like a lookup table that could help us, just on its side. I’ll switch that to a longer format.
| Labels | |
|---|---|
| question_label | question_fruit |
| Q1_1 | Which fruit do you prefer? - apple |
| Q1_2 | Which fruit do you prefer? - orange |
| Q1_3 | Which fruit do you prefer? - pear |
| Q1_4 | Which fruit do you prefer? - grape |
| Q1_5 | Which fruit do you prefer? - banana |
Now we have each of the fruit names in the fruit column. We can more easily work down that column to get rid of the question. It’s easier to work down a single column than to specify all the columns by name to work across. That is particularly true if we add more options in future (adding “dragon fruit” for example to make a Q1_6 option).
We can now separate the fruit name out using the pattern that the question is separated from the fruit name by the - character. We will throw away the question part, keeping just the name of the fruit.
| Labels | |
|---|---|
| question_label | fruit |
| Q1_1 | apple |
| Q1_2 | orange |
| Q1_3 | pear |
| Q1_4 | grape |
| Q1_5 | banana |
Now we have a lookup table that will help us to translate between the column headers in the responses and the actual fruit being ranked.
Turning back to the responses table (dropping the labels row) we have:
| ResponseId | Q1_1 | Q1_2 | Q1_3 | Q1_4 | Q1_5 |
|---|---|---|---|---|---|
| R_2Gv45TBz2xAZBgw | 1 | 2 | 3 | 4 | 5 |
| R_2Dc4B4z51U9BbVu | 3 | 5 | 2 | 1 | 4 |
| R_2VjavSpNBqeI26l | 5 | 4 | 3 | 2 | 1 |
To use the lookup table it will be a lot easier to move the column headers into cells, rather than trying to work with the column headers. So we can transform this to a longer format, with a column for the question label and a column to hold the actual ranking.
| Responses | ||
|---|---|---|
| ResponseId | question | ranking |
| R_2Gv45TBz2xAZBgw | Q1_1 | 1 |
| R_2Gv45TBz2xAZBgw | Q1_2 | 2 |
| R_2Gv45TBz2xAZBgw | Q1_3 | 3 |
| R_2Gv45TBz2xAZBgw | Q1_4 | 4 |
| R_2Gv45TBz2xAZBgw | Q1_5 | 5 |
| R_2Dc4B4z51U9BbVu | Q1_1 | 3 |
| R_2Dc4B4z51U9BbVu | Q1_2 | 5 |
| R_2Dc4B4z51U9BbVu | Q1_3 | 2 |
| R_2Dc4B4z51U9BbVu | Q1_4 | 1 |
| R_2Dc4B4z51U9BbVu | Q1_5 | 4 |
| R_2VjavSpNBqeI26l | Q1_1 | 5 |
| R_2VjavSpNBqeI26l | Q1_2 | 4 |
| R_2VjavSpNBqeI26l | Q1_3 | 3 |
| R_2VjavSpNBqeI26l | Q1_4 | 2 |
| R_2VjavSpNBqeI26l | Q1_5 | 1 |
Now we can recode the question by looking it up in the labels table, adding a fruit column.
| ResponseId | question | fruit | ranking |
|---|---|---|---|
| R_2Gv45TBz2xAZBgw | Q1_1 | apple | 1 |
| R_2Gv45TBz2xAZBgw | Q1_2 | orange | 2 |
| R_2Gv45TBz2xAZBgw | Q1_3 | pear | 3 |
| R_2Gv45TBz2xAZBgw | Q1_4 | grape | 4 |
| R_2Gv45TBz2xAZBgw | Q1_5 | banana | 5 |
| R_2Dc4B4z51U9BbVu | Q1_1 | apple | 3 |
| R_2Dc4B4z51U9BbVu | Q1_2 | orange | 5 |
| R_2Dc4B4z51U9BbVu | Q1_3 | pear | 2 |
| R_2Dc4B4z51U9BbVu | Q1_4 | grape | 1 |
| R_2Dc4B4z51U9BbVu | Q1_5 | banana | 4 |
| R_2VjavSpNBqeI26l | Q1_1 | apple | 5 |
| R_2VjavSpNBqeI26l | Q1_2 | orange | 4 |
| R_2VjavSpNBqeI26l | Q1_3 | pear | 3 |
| R_2VjavSpNBqeI26l | Q1_4 | grape | 2 |
| R_2VjavSpNBqeI26l | Q1_5 | banana | 1 |
Now we are really close! We data in a tidy long format. We can drop the question column; we don’t need it any more and it’s just an artifact of the qualtrics survey anyway.
| ResponseId | fruit | ranking |
|---|---|---|
| R_2Gv45TBz2xAZBgw | apple | 1 |
| R_2Gv45TBz2xAZBgw | orange | 2 |
| R_2Gv45TBz2xAZBgw | pear | 3 |
| R_2Gv45TBz2xAZBgw | grape | 4 |
| R_2Gv45TBz2xAZBgw | banana | 5 |
| R_2Dc4B4z51U9BbVu | apple | 3 |
| R_2Dc4B4z51U9BbVu | orange | 5 |
| R_2Dc4B4z51U9BbVu | pear | 2 |
| R_2Dc4B4z51U9BbVu | grape | 1 |
| R_2Dc4B4z51U9BbVu | banana | 4 |
| R_2VjavSpNBqeI26l | apple | 5 |
| R_2VjavSpNBqeI26l | orange | 4 |
| R_2VjavSpNBqeI26l | pear | 3 |
| R_2VjavSpNBqeI26l | grape | 2 |
| R_2VjavSpNBqeI26l | banana | 1 |
Now, remember the output format that we eventually wanted?
| response_id | fruit_in_order |
|---|---|
| response1 | apple, orange, pear, grape, banana |
| response2 | banana, grape, pear, orange, apple |
We can get there by nesting the fruit! We do need to make sure that we order the list by the ranking column. Here I show that using the approach used in grouping, with red lines to separate the groups.
| ResponseId | fruit | ranking |
|---|---|---|
| R_2Dc4B4z51U9BbVu | grape | 1 |
| R_2Dc4B4z51U9BbVu | pear | 2 |
| R_2Dc4B4z51U9BbVu | apple | 3 |
| R_2Dc4B4z51U9BbVu | banana | 4 |
| R_2Dc4B4z51U9BbVu | orange | 5 |
| R_2Gv45TBz2xAZBgw | apple | 1 |
| R_2Gv45TBz2xAZBgw | orange | 2 |
| R_2Gv45TBz2xAZBgw | pear | 3 |
| R_2Gv45TBz2xAZBgw | grape | 4 |
| R_2Gv45TBz2xAZBgw | banana | 5 |
| R_2VjavSpNBqeI26l | banana | 1 |
| R_2VjavSpNBqeI26l | grape | 2 |
| R_2VjavSpNBqeI26l | pear | 3 |
| R_2VjavSpNBqeI26l | orange | 4 |
| R_2VjavSpNBqeI26l | apple | 5 |
Now we can see that we want the fruit for each group, joined together into a comma-separated list.
| ResponseId | fruit_in_order |
|---|---|
| R_2Dc4B4z51U9BbVu | grape, pear, apple, banana, orange |
| R_2Gv45TBz2xAZBgw | apple, orange, pear, grape, banana |
| R_2VjavSpNBqeI26l | banana, grape, pear, orange, apple |
Summary
So this shows how our basic data transforms can be combined:
- We excluded rows and columns
- We extracted parts of fields into new columns
- We transformed from wide to long (a few times!)
- We created then used a recode/lookup table
- We grouped and sorted data within those groups
- We nested data
I think it’s entirely reasonable to ask: why doesn’t Qualtrics just export these data in a more usable way. Well, I don’t know the particular answer to that, but Qualtrics export format has to cope with a lot of variety in question type, as well as including meta-data, call within a single CSV download. We could try calling qualtrics support, but I doubt they’ll change their export format just for us :)
The reality is that we have to work with the data as we find it, then combine our data transformation verbs together to get where we want to go.