23 Parameterized SQL queries from Python
Parameterized queries allow us to insert variables into our SQL queries. This is analogous to f-strings and the .format method.
Parameterized queries have two important functions:
- They “sanitize” inputs from users to protect against malicious queries reaching the database.
- They simplify re-using queries inside loops.
24 Using placeholders in queries.
Sometimes we have values in strings and ints in python that we want to use within queries. We might have gotten input from the terminal, or a web-form. Very often we’re working with data we’ve read from a CSV file and are inserting into the database.
In these cases we can’t just work with hard-coded SQL queries (such as SELECT * FROM venues) but we have to put data into the queries. This is very similar to interpolating variables into strings, as we did with the Michael Finegan poem, but there are a few differences. Whether the data are typed in by someone or come from a CSV file, we have to treat them as potentially dangerous, because they could have special characters that could do mischief in the database (see below).
For interpolating strings we’ve used + and we’ve used {} and .format or f"". For sql neither are sufficient, since if we’re inserting a number we don’t need quotes but if we’re inserting a string we do. Possibly more importantly, we also have to make sure we’re not inserting strings that might hold SQL that tries to cause problems. One of the most common security flaws is called an “SQL Injection Attack” and it can be avoided through parameterized queries. See XKCD’s excellent comic which explains this. Seriously, read that comic and read the explanation. I’ll wait.
In the first example we will be working with just one input to interpolate (aka stick into the query). We set up a dictionary (called param_dict by convention) with keys, then use those keys in the placeholder and pass both the placeholder and the param_dict to cursor.execute().
Note that the placeholder here is not {key_name} as with .format and f"" but for duckdb it is $key_name This is what you will use in your project.
new_venue_params = {"new_name": "Rocking new venue2",
"new_capacity": 10000 }
new_venue_sql = """INSERT INTO venues (name, capacity)
VALUES ($new_name, $new_capacity)"""
with duckdb.connect('duckdb-file.db') as con:
con.execute(new_venue_sql, new_venue_params)You can check that the INSERT worked by using
%%sql
SELECT * FROM VENUESThe benefit of placeholders is that we can iterate over a list and run the query for each dictionary. For example:
venues = [{'new_capacity': 700, 'new_name': 'AMD2'},
{'new_capacity': 2000, 'new_name': 'Honda2'},
{'new_capacity': 2300, 'new_name': 'Austin Kiddie Limits2'},
{'new_capacity': 2000, 'new_name': 'Austin Ventures2'}]
new_venue_sql = """INSERT INTO venues (name, capacity)
VALUES ($new_name, $new_capacity)"""
with duckdb.connect('duckdb-file.db') as con:
for row in venues:
con.execute(new_venue_sql, row)You will notice that this is not creating new id values for the rows. We will fix this in a minute.
Where this becomes really useful is substituting data drawn from different rows of a CSV file. Each row from the CSV will come in as a dictionary, so we use the names of the keys as placeholders in our SQL query.
At this point we will switch from our class_music_festival database over to our enrollments database that we used to learn about INSERT logs.
In that class we were trying to move data from this single csv (which you can download and upload into DataCamp):
Do your notebook setup as at the top of Chapter 22.
students_classes.csv
------------
class_name, student_name, semester
Divination, Hermione, Fall
Divination, Harry, Fall
Potions, Ron, Springinto these tables:
students(id, name)
------------------
classes(id, name)
-----------------
enrollments(id, semester, student_id, class_id)
-----------------------------------------------For our first effort we will first create the students table.
%%sql
DROP TABLE IF EXISTS students;
DROP SEQUENCE IF EXISTS seq_student_id;
-- create sequence then use it as default
CREATE SEQUENCE seq_student_id START 1;
CREATE TABLE students (
id INT PRIMARY KEY DEFAULT NEXTVAL('seq_student_id'),
name TEXT
);We can now read the CSV file and insert all the student names. We are going to do this row by row (rather than reading the whole CSV into memory, then inserting it all into the database). This means we need two with blocks. One for the csv reading and one for the database connection.
with duckdb.connect('duckdb-file.db') as con:
sql_placeholder = "INSERT INTO students(name) VALUES ($new_name)"
with open('students_classes.csv') as csvfile:
myCSVReader = csv.DictReader(csvfile, delimiter=",", quotechar='"')
for row in myCSVReader:
print(row)
param_dict = {'new_name': row['student_name']}
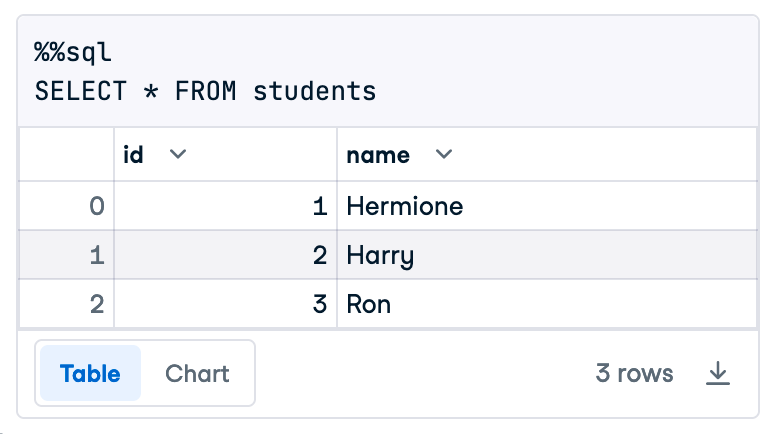
con.execute(sql_placeholder, param_dict)Again run SELECT * FROM students in an %%sql cell to see the results, which should look like this:
24.1 Getting id
To obtain the id assigned by adding a row to a table with a sequence, we add RETURNING id to our INSERT query.
with duckdb.connect('duckdb-file.db') as con:
sql_placeholder = "INSERT INTO students(name) VALUES ($new_name) RETURNING id"
with open('students_classes.csv') as csvfile:
myCSVReader = csv.DictReader(csvfile, delimiter=",", quotechar='"')
for row in myCSVReader:
param_dict = {'new_name': row['student_name']}
con.execute(sql_placeholder, param_dict)
new_student_id = con.fetchone()[0]
print(f"Received {new_student_id} for {row['student_name']}")If you run this multiple times your will be creating multiples for the students, but we’ll deal with that in a minute.
You may be wondering why we need to create param_dict; why can’t we just use row directly? With some databases we can, but DuckDB’s python interface gets upset if there are extra keys in the dict passed to execute, keys that are not in the placeholder_sql. So param_dict is needed. In any case it is useful to be certain of different name forms.
In this code we actually have three ways to refer to fields:
- CSV column names in the incoming csv file (e.g.
student_name) - The keys in the param_dict (e.g.,
new_name) which match up with the placeholders (e.g.,$new_name) - Table column names The column names in duckdb (e.g.
name)
The progression here is:
csv column name → row dict keys → param_dict keys → table columns.
Four key rules:
rowwill always have the same keys as the columns in the csv file.- The keys in
param_dicthave to match the placeholders in the sql string (e.g.,$new_name) - The names in the first part of the
INSERThave to match the names in the table e.g.,INSERT INTO table_name(table_column1, table_column2) - The order of the placeholders in the
INSERThas to match the order of the table columns.