13 CREATE, INSERT, UPDATE, DELETE
There are queries beyond SELECT:
- CREATE (to make new databases and tables)
- INSERT (to add new rows)
- UPDATE (to change data)
- DELETE (to remove rows)
Each of them reuses syntax from SELECT but instead of leaving the database untouched, each of them changes data in the database.
To get these working we need to move beyond the file.csv approach we’ve been using this semester in DataCamp. In the background that is setting up a DuckDB database and loading the csv files in as tables. But now we need to change data, so we need to create database (and not just query csv files).
At the moment I can’t see a way in DataCamp to do this using their Database tab; which seems to require an external database on a different server. But we can use Python cells (as we will later this semester) to set up and query a database. Unfortunately, I also can’t see a way to use DataCamp’s lovely SQL cell type, so we’ll use a python cell that starts with %%sql through something called “Python magics” (It’s not magic, it’s SCIENCE. Or ENGINEERING, but that doesn’t quite have the same ring.)
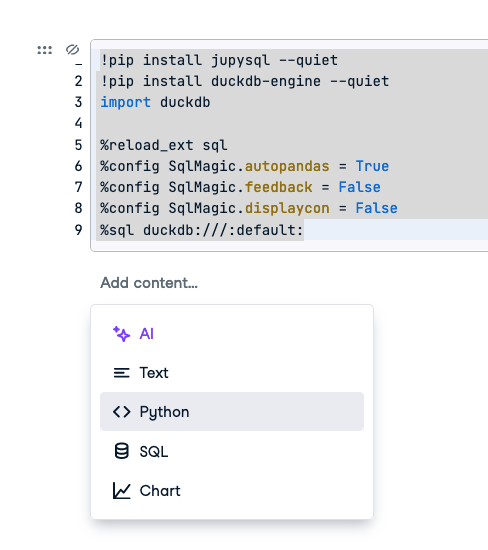
To get this working in a DataCamp workspace you will need to copy this into the first cell:
!pip install jupysql --quiet
!pip install duckdb-engine --quiet
import duckdb
%reload_ext sql
%config SqlMagic.autopandas = True
%config SqlMagic.feedback = False
%config SqlMagic.displaycon = False
%sql duckdb:///duckdb-file.dbThat code installs packages (using pip), imports them into the current workspaces (import) and then sets up the SQL Magic so that our %%sql cells will work. The duckdb:///duckdb-file.db creates a database, where the data is held in a file called duckdb-file.db. You will see that file in your workspace, along with some working files (e.g., duckdb-file.db.wal which is some internal of duckdb).
Now we can run SQL queries. Remember to choose a python cell and not an SQL cell.
And copy in this “Hello World” command (which just tells DuckDB to return a constant). The %%sql followed by a newline allows you to create multiline SQL queries, so we can use the query layout that we have so far.
%%sql
SELECT 'Hello World' AS duck_db_column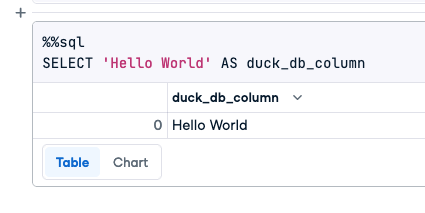
We can load data into the database directly from a csv file (which is what DataCamp has been doing in the background) using some DuckDB specific SQL. First download the hobbies.csv and majors.csv files then upload them to your workspace. Then we can use some new SQL commands to load them.
DROP TABLE IF EXISTS hobbies;
CREATE TABLE hobbies AS FROM read_csv_auto('hobbies.csv', header=true);
DROP TABLE IF EXISTS majors;
CREATE TABLE majors AS FROM read_csv_auto('majors.csv', header=true);DROP TABLE IF EXISTS makes sure we don’t have a previously created hobbies table (so if you re-run the notebook from the top it will drop any changed data and re-load the hobbies.csv file). This makes the notebook “idempotent” a fancy word that means “able to be run from the top and always end up at a known state”.
We can now do our queries from the last class, but remember to use python cells and add %%sql
%%sql
SELECT COALESCE(majors.name, hobbies.name) AS name, hobby, major
FROM hobbies
FULL OUTER JOIN majors ON hobbies.name = majors.name14 INSERT
INSERT requires us to provide a list of columns and a list of data to go into each column.
INSERT INTO table_name(column1, column2) VALUES (data1, data2)We do not have to provide data for all columns and we don’t have to use the same order as the columns were created.
Imagine a database with Book has many Author so we have three tables (books, authors, and books_authors). A convenient syntax for quickly describing tables in text is `tablename(id_col,other_cols…):
books(id, title)
authors_book(author_id,book_id)
authors(id, name)%%sql
CREATE TABLE books (
id INT PRIMARY KEY,
title TEXT
)%%sql
CREATE TABLE authors_books (
author_id INTEGER,
book_id INTEGER
)%%sql
CREATE TABLE authors (
id INT PRIMARY KEY,
name TEXT
)To insert the data that “Emily Bronte” wrote “Wuthering Heights” (assuming neither were in the database already) we’d do:
%%sql
INSERT INTO books(id, title) VALUES (7, 'Wuthering Heights')%%sql
INSERT INTO authors(id, name) VALUES (23, 'Emily Bronte')%%sql
INSERT INTO authors_books(book_id, author_id) VALUES (7, 23)In these examples I’m providing a manual id (7 and 23 above). However the database can also provide an integer value for id automatically. That is done in different ways in different databases (unfortunately!). In DuckDB we have to do
%%sql
CREATE SEQUENCE seq_bookid START 1;And then use that sequence value in our query.
%%sql
INSERT INTO books(id, title) VALUES (nextval('seq_bookid'), 'Wuthering Heights')And we can see the results with:
%%sql
SELECT * FROM booksIf you run the insert multiple times you’ll see the key incrementing.
You can combine creating a table with creating the sequence too:
%%sql
DROP TABLE IF EXISTS books;
CREATE SEQUENCE seq_bookid START 1;
CREATE TABLE books (
id INT PRIMARY KEY DEFAULT NEXTVAL('seq_bookid'),
title TEXT
);And then you should be able to run just:
%%sql
INSERT INTO books(title) VALUES ('Wuthering Heights')This can be very useful, but if we want to use the generated id to describe relationships we have to obtain the id that the server provides. We can get that in two ways. One with SQL and one with python (which we’ll learn later)
%%sql
SELECT currval('seq_bookid');For example, imagine we have a csv file with these data:
author,title
"Chimamanda Ngozi Adichie","We Should All Be Feminists"
"Wu Cheng'en","Journey to the West"
"Kim Man-jung","The Nine Cloud Dream"For each row, we would have to do these queries (changing the text each time):
%%sql
INSERT INTO books(title) VALUES ('Journey to the West');followed by
%%sql
SELECT currval('seq_bookid');then remember the id assigned (let’s say we got back 120) (Note that a doubled single quote is the way we tell postgres to include a single quote inside a text field)
%%sql
INSERT INTO authors(name) VALUES ('Wu Cheng''en');%%sql
SELECT currval('seq_bookid');then remember the id assigned (let’s say we got back 1007).
Finally we can then make the connection:
INSERT INTO authors_books(book_id, author_id) VALUES (120, 1007);So each row in that csv would require at least three queries adding data to three tables. so don’t think of a 1-to-1 mapping between a csv and a table in the database. We aren’t uploading csv files as we might to Box, we are going to read csv files, understand their meaning and transform them to express that meaning in the SQL tables.
Later in the course we will return to this, because it can take more than this number of queries, since we don’t want to create duplicate records (ie we create a book just once, we create an author just once). That means when we see the name again, we have to use SELECT queries with a WHERE clause to find the id that was assigned before.
We will cover these sequences of SELECT and INSERT queries when we are doing them via Python later in the course.
Note that inserting lots of data (like millions of rows) using this approach can be slow. I examine quicker ways to insert data into databases in the “Advanced Tips” Module toward the end of the course.
15 UPDATE data already in the database
UPDATE allows us to change data already in the database. These queries work by first identifying rows to be changed (which re-uses what we’ve learned about the WHERE clause already) and then getting new values for particular columns.
For example, we could change the spelling of Emily Bronte’s name to include a diaersis over the final e. We first find the record we want to update using SELECT.
SELECT authors.id
FROM authors
WHERE name = 'Emily Bronte'The we use the id returned (23) to effect the change:
UPDATE authors
SET name = 'Emily Brontë' -- Change spelling to fancy style
WHERE authors.id = 23Here we’re being cautious to minimize and check our edits to the database by using the SELECT first and using id to identify the records to change.
While it is often sensible to use an id (or a group of ids) in the WHERE clause to be sure of the rows to be changed, any WHERE clause will work. For example, if we had a last name column (which we don’t) we could change all the Bronte to Brontê with one query (the database will tell you how many rows were changed).
UPDATE authors
SET lastname = 'Brontë'
WHERE lastname = 'Bronte' -- Change all the Brontes at once.We can also change more than one column at a time, by providing a comma separated list of fields and value pairs in the SET clause. For example we could change both the venue and the band for a performance (keeping the start and end times).
UPDATE authors
SET firstname = 'Emile', lastname = 'Bronté'
WHERE id = 2btw, I think the lack of consistency between INSERT (two comma separated lists of columns and values) and UPDATE SET (one comma separated list column = value) is confusing. I don’t know why it is that way.
The question often arises about whether we can do UPDATEs based on joins (adding a FROM/JOIN clause). In general yes, that is possible. However, it is confusing (am I updating the temporary join table or the underlying tables?) and can be hard to read and to check. I recommend finding the ids of the rows that you want to update (using a SELECT), then updating those using that SELECT in a sub-query.
For example if we wanted to update the fee for all bands playing in the BMI venue, adding $100 to each band’s fee.
-- Find the list of band ids.
SELECT bands.id
FROM bands
JOIN performances
ON bands.id = performances.band_id
JOIN venues
ON performances.venue_id = venues.id
WHERE venues.name = 'BMI'
-- UPDATE using a sub-query to provide the list of ids.
UPDATE bands
SET bands.fee = bands.fee + 100
WHERE bands.id IN (
SELECT bands.id
FROM bands
JOIN performances
ON bands.id = performances.band_id
JOIN venues
ON performances.venue_id = venues.id
WHERE venues.name = 'BMI'
)16 DELETE
Finally we can delete data in the database. The DELETE statement is a SELECT statement (to find the rows you want to delete) but rather than specifying the columns you want, change the SELECT clause to DELETE. Using SELECT first helps you ensure that you will delete the right rows! No Undo button (at least not in the way we have SQL set up, undo is possible using a feature called “transactions”).
SELECT * FROM books WHERE id = 23
DELETE FROM books WHERE id = 23In this class we will have to manually delete references to this rows from tables with foreign keys.
DELETE FROM books_authors WHERE book_id = 23Note that one would need to check if the author had written any other books before deleting the author. UPDATEs and DELETEs can’t be undone, so only delete using ids and do SELECTs first.
It is possible to automatically delete linked rows using “cascading deletes” but usually there are other things that need to be checked and changed, so largely the logic for that has moved out of the database and is implemented through python, ruby, or php. It is worth, though, thinking briefly about those situations.
17 Delete Emily Bronte?
The instruction “Delete Emily Bronte” seems straightforward.
SELECT *
FROM people
WHERE people.name = 'Emily Bronte'
-- Check that it all looks good and ok to delete, no unexpected rows.
DELETE
FROM people
WHERE people.name = 'Emily Bronte'However, deleting Emily from the people table does not remove her id from the database entirely. For example it would leave her id in the book_roles table associated with books she had written (and potentially in other tables) Even if we delete all of her book_roles what ought to happen to books that she co-authored with others, should they now also be removed? (Are we erasing her from history?) If we don’t then we have erroneous information about those books.
Let’s say that we want to remove any books (and book_roles) that were associated with Emily Bronte. In these situations it is best to work backwards from the further location (ie the Book), back towards the Person. (It’s easier to find the books that Emily Bronte was involved in before Emily Bronte’s record in the person table is deleted!)
-- Find all the books associated with Emily Bronte in any form.
SELECT *
FROM people
WHERE people.name = 'Emily Bronte'
-- Navigate over to books, this gets any books associated with Emily.
SELECT *
FROM people
JOIN book_roles
ON book_roles.person_id = people.id
JOIN books
ON book_roles.book_id = books.id
WHERE people.name = 'Emily Bronte'
-- Just get books.id
-- This returns a list of book ids like (7, 23, 45)
SELECT books.id
FROM people
JOIN book_roles
ON book_roles.person_id = people.id
JOIN books
ON book_roles.book_id = books.id
WHERE people.name = 'Emily Bronte'
-- Now use that list to do the delete from books.
-- Could write the results of last query down
-- (I just made these numbers up) and use like this:
SELECT *
FROM books
WHERE books.id IN (7, 23, 45)
-- But it's better to use a sub-query that generates the list.
-- Here I've just substituted the query two up for the list of ids.
SELECT *
FROM books
WHERE books.id IN (
SELECT books.id
FROM people
JOIN book_roles
ON book_roles.person_id = people.id
JOIN books
ON book_roles.book_id = books.id
WHERE people.name = 'Emily Bronte'
)
-- Now convert the SELECT * to DELETE.
DELETE
FROM books
WHERE books.id IN (
SELECT books.id
FROM people
JOIN book_roles
ON book_roles.person_id = people.id
JOIN book
ON book_roles.book_id = books.id
WHERE people.name = 'Emily Bronte'
)
-- Now delete all book_roles associated with those books
--
SELECT *
FROM people
JOIN book_roles
ON book_roles.person_id = people.id
WHERE people.name = 'Emily Bronte'
-- Get book_ids for those.
SELECT book_roles.book_id
FROM people
JOIN book_roles
ON book_roles.person_id = people.id
WHERE people.name = 'Emily Bronte'
-- Now find all remaining records associated with those books.
SELECT *
FROM book_roles
WHERE book_roles.book_id IN (
SELECT book_roles.book_id
FROM people
JOIN book_roles
ON book_roles.person_id = people.id
WHERE people.name = 'Emily Bronte'
)
-- Note that this deletes a supplier role as well. Possibility that
-- we "orphan" a supplier person if they are no longer associated
-- with the book. See below.
-- And convert to a delete.
DELETE
FROM book_roles
WHERE book_roles.book_id IN (
SELECT book_roles.book_id
FROM people
JOIN book_roles
ON book_roles.person_id = people.id
WHERE people.name = 'Emily Bronte'
)
-- Finally delete Emily.
DELETE
FROM people
WHERE people.name = 'Emily Bronte'Phew!