15 Inner and Outer joins
Often we want to combine data from different tables. So far we’ve done this with id columns and using using JOIN on its own. Now we will learn there are a few differen kinds of JOIN.
Take this example:
hobbies
| name | hobby |
|---|---|
| Shuyen (both tables) | dancing |
| Brian (both tables) | dancing |
| Adnan (hobbies_only) | running |
majors
| name | major |
|---|---|
| Shuyen (both tables) | Art |
| Brian (both tables) | Theater |
| Yungsheng (majors only) | English |
There are actually quite a few different ways to bring these data together (and the files are available: hobbies.csv and majors.csv).
Notice that the students in each table are overlapping. Some are in both tables (Shuyen and Brian), but others are only in one of the tables (Adnan in hobbies, Yungsheng in majors).
One thing we can’t do is (pretending we are in Excel land) we can’t just copy the major column and paste it next to the student_hobbies columns. If we do that, we will end up with an incorrect row that claims that Adnan is in the English major. So Yungsheng’s data ends up on Adnan’s row.
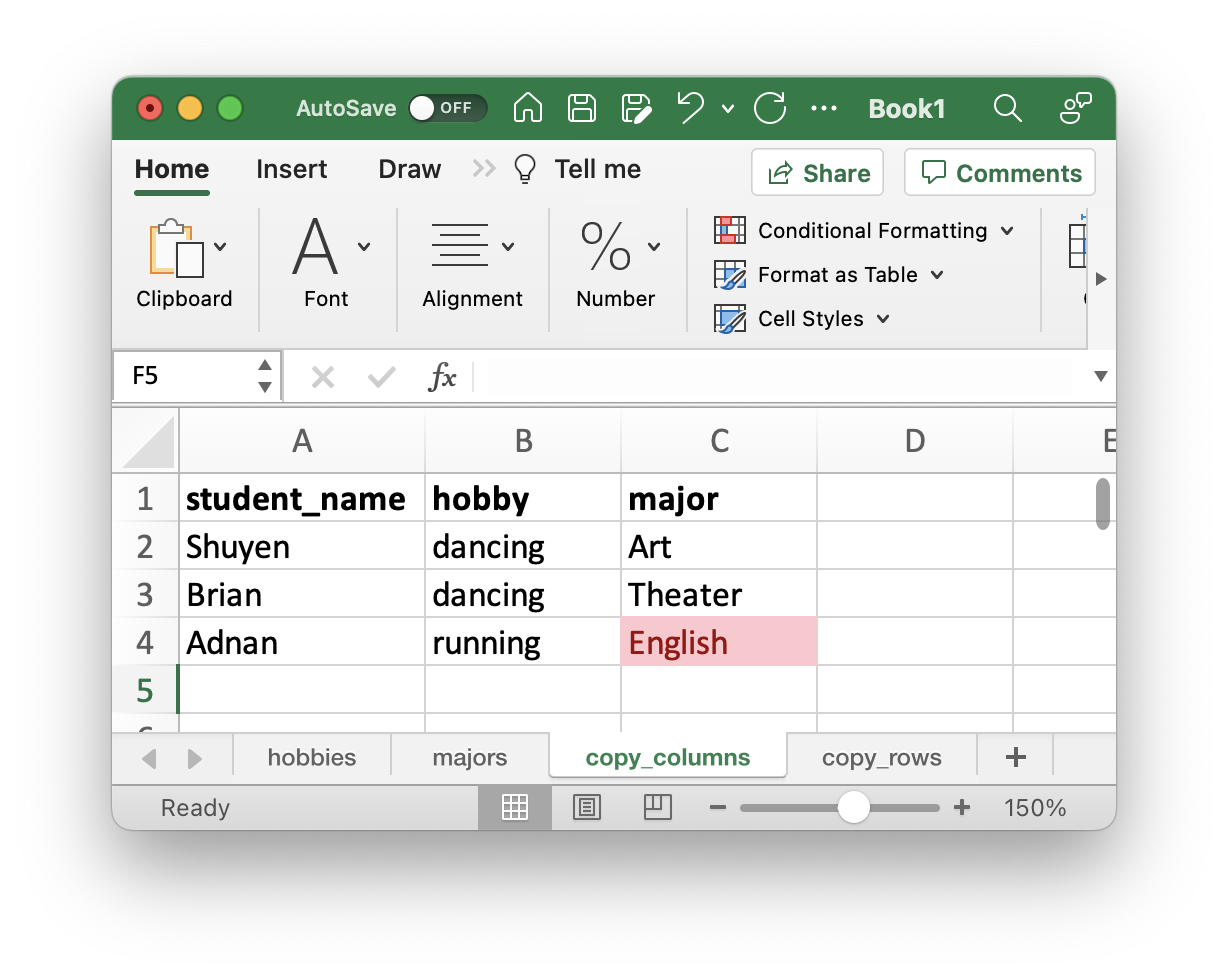
We also can’t copy both columns and paste them underneath. If we do that the values from major will end up in the hobby column.
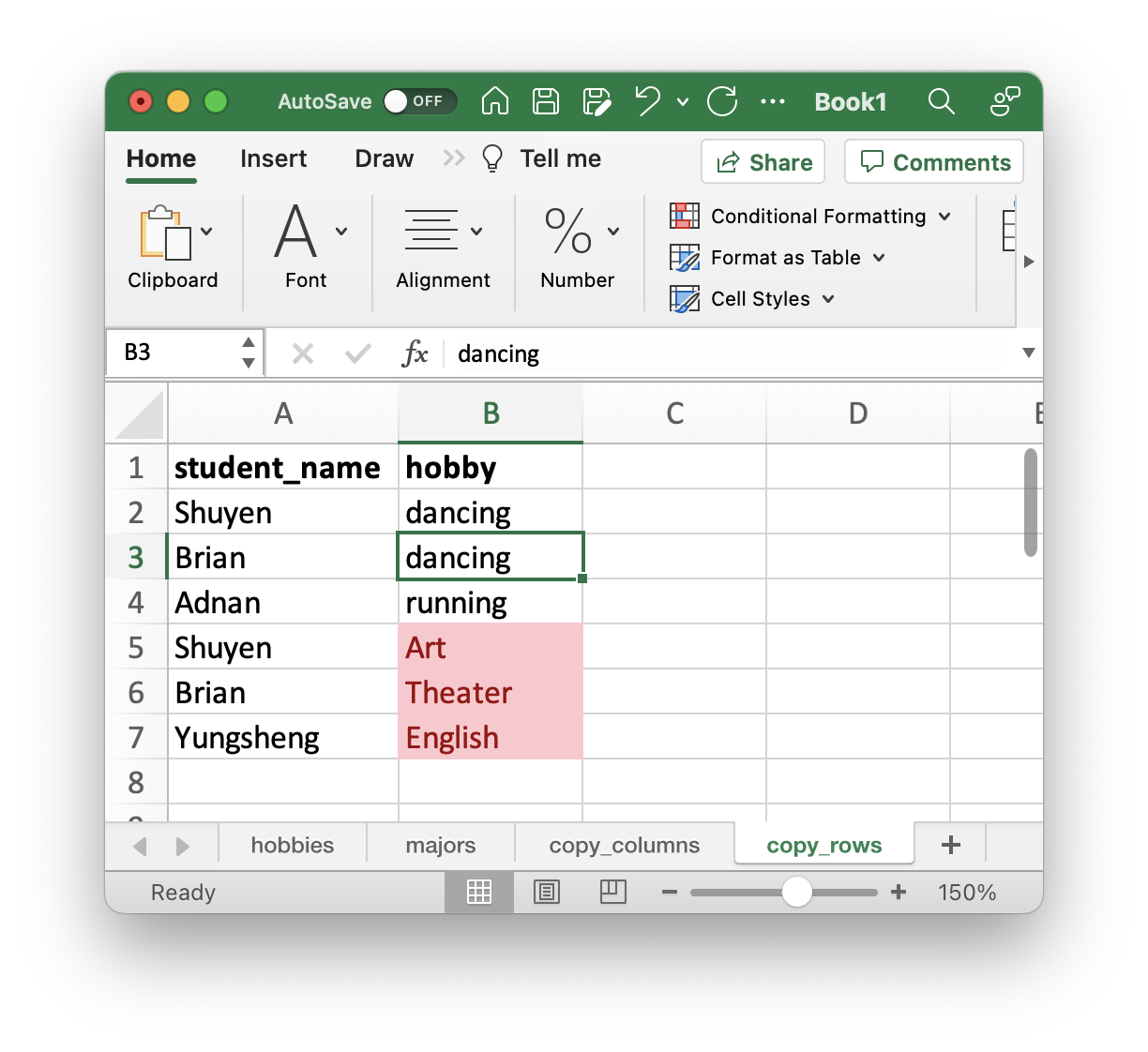
But SQL databases know ways to combine the tables that preserve the meaning of the data.
We will look at four different ways to combine these tables: 1) FULL JOIN, 2) LEFT JOIN, 3) RIGHT JOIN, and 4) INNER JOIN
|
FULL JOIN 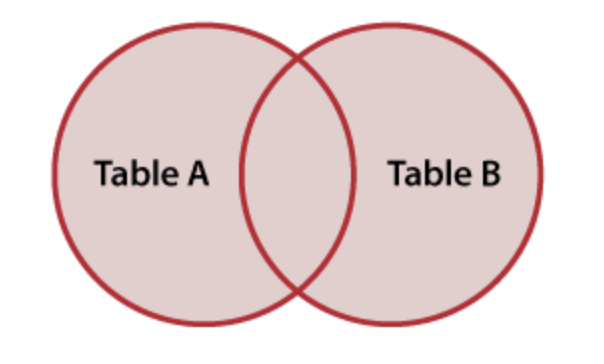
|
|
|
LEFT JOIN 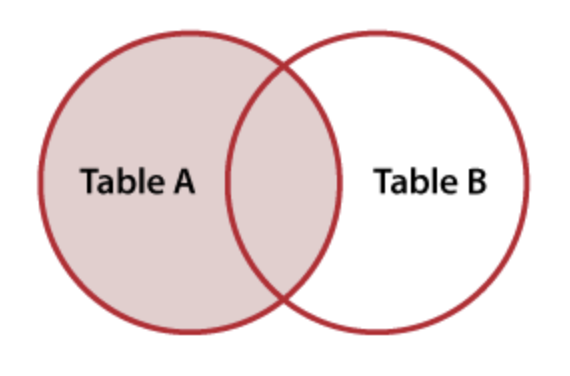
|
RIGHT JOIN 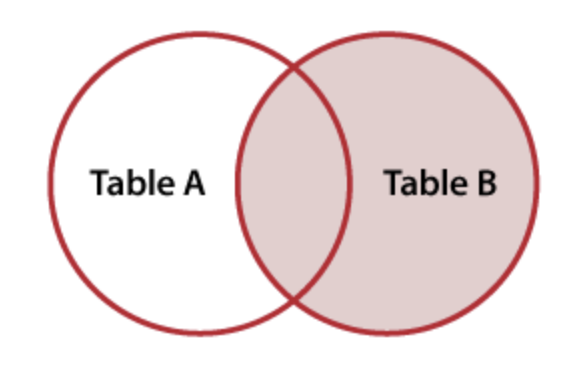
|
|
INNER JOIN 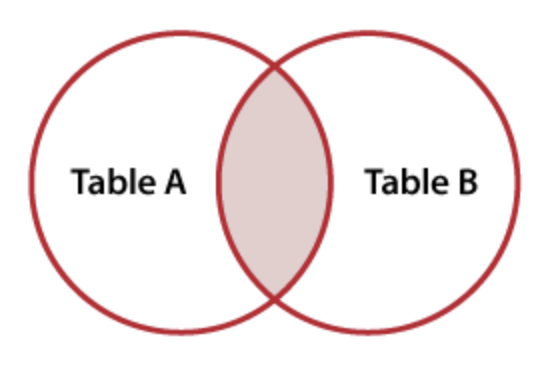
|
|
Images from https://learnsql.com/blog/sql-joins/
FULL JOIN
The first keeps all of the data, matching up rows and adding NULL values where rows are only in one table or the other. This is called the FULL JOIN.
SELECT *
FROM hobbies
FULL JOIN majorsfull_join_result
| name | hobby | major |
|---|---|---|
| Shuyen (both tables) | dancing | Art |
| Brian (both tables) | dancing | Theater |
| Adnan (hobbies_only) | running | NULL |
| Yungsheng (majors only) | NULL | English |
LEFT and RIGHT JOIN
We can also keep all of the data from one table, and add in only the matching data from the other table. This is called the LEFT JOIN or the RIGHT JOIN. The direction just points to which table we will keep all the rows from.
LEFT JOIN
SELECT *
FROM hobbies
LEFT JOIN majorsleft_join_result
| name | hobby | major |
|---|---|---|
| Shuyen (both tables) | dancing | Art |
| Brian (both tables) | dancing | Theater |
| Adnan (hobbies_only) | running | NULL |
RIGHT JOIN
SELECT *
FROM hobbies
RIGHT JOIN majorsright_join_result
| name | hobby | major |
|---|---|---|
| Shuyen (both tables) | dancing | Art |
| Brian (both tables) | dancing | Theater |
| Yungsheng (majors only) | NULL | English |
These are really useful when we have data in a table about things and we want to “bring over” any data we have about those things.
A RIGHT JOIN is identical to a LEFT JOIN with the tables reversed in order. This makes it almost never used as people would just rewrite it as a LEFT JOIN. So one generally doesn’t come across RIGHT JOIN. ie:
majors RIGHT JOIN hobbiesis identical to
hobbies LEFT JOIN majorsINNER JOIN
Finally, our fourth option is to only keep rows that have data in both tables. This is called an INNER JOIN.
inner_join_result
| name | hobby | major |
|---|---|---|
| Shuyen (both tables) | dancing | Art |
| Brian (both tables) | dancing | Theater |
Notice that, in some sense, the INNER JOIN drops data? Neither Adnan nor Yungsheng show up in these results at all. Sometimes that is appropriate, sometimes that is problematic.
Inner vs Outer?
Joins are frequently talked about as being two kinds, inner and outer.
FULL, LEFT and RIGHT are all OUTER joins.
Because LEFT JOIN is by far the most used, if someone says just “outer join” then they almost always mean LEFT JOIN but OUTER JOIN on its own will throw an error.
INNER JOIN is the only inner join (there is only one way to include only the rows that match), it is used frequently enough that JOIN with no other word means INNER JOIN.
Yes, so far in the course we have been doing INNER JOIN without calling it that.
JOIN synonyms
Square brackets shows optional part.
FULL [OUTER] JOIN
LEFT [OUTER] JOIN -- Often say "outer join"
RIGHT [OUTER] JOIN
[INNER] JOIN -- might just say just "join"Many people are confused about the language here.
It is very common for people to think that a LEFT JOIN is not a kind of OUTER join. They may think that only a FULL OUTER JOIN is an OUTER JOIN.
They may become enraged if you insist on this.
Try to get comfortable with the two most common joins. INNER JOIN and LEFT JOIN. One useful way to think of this is:
INNER JOIN: All the rows where there is a match (and none of the rows where there is no match) LEFT JOIN: Keep everything in the left table, and add any matching rows from the other table. This is sometimes called “adding matching data, if any” and is used to do “lookups”.
Be aware that some people will say “join” when they are talking, but they will by default write LEFT JOIN, so they actually mean LEFT JOIN but they just say “join” (even though JOIN on it’s own is an inner join).
I dunno, it’s a mess. Don’t blame me.
At least LEFT JOIN never drops data (from the left hand table at least!)
Join conditions (ON and USING)
When we join tables we have to say which columns we want to join on. So far we have done this using the ON clause.
In the examples above it was implicit that we were joining using the name column (as that was the only one with any matches). We do have to tell SQL this, so we use
ON left_table.column = right_table.columnIn that way our LEFT JOIN above would become:
SELECT *
FROM hobbies
LEFT JOIN majors ON hobbies.name = majors.nameThere is a special shorthand when the column name is the same in both tables, USING column_name. Making it:
SELECT *
FROM hobbies
LEFT JOIN majors USING (name) Note, though, that when we use ON we will get back all of the columns from both tables. In DuckDB this means you will get name and name_2.
This is not problematic when doing a LEFT JOIN because the name_2 column will always have only repeated content, so you can just drop or ignore it. But if you are doing a FULL OUTER JOIN you will have the names from the left table in name and the names from the right table in name_2.
One advantage of USING is that you will only get one name column back. But it only works when columns are named exactly the same, something that often doesn’t work (including when working with id and foreign_id columns).
In this (rare but confusing) case, we can use COALESCE to merge the name and name_2 columns:
SELECT COALESCE(majors.name, hobbies.name) AS name, hobby, major
FROM hobbies
FULL OUTER JOIN majors ON hobbies.name = majors.nameCOALESCE works by looking at each row, working left to right in the columns you give it, taking the first non-null value it encounters. Given that, the order you put the columns in the COALESCE doesn’t matter, when working with a FULL OUTER JOIN.
Looking up values
One important use of JOIN is to lookup the value of some code, such as abbreviations. This is a little like “find and replace,” using a second table to lookup values, doing many different “find and replace” all at once.
Consider these data:
countries
| english_name | iso_code3 | iso_code2 |
|---|---|---|
| China | CHN | CN |
| Australia | AUS | AU |
| United States of America | USA | US |
Now we can use these to convert a iso_code to an english name for a country. Consider:
olympic_medals
| country | year_occured | medal_count |
|---|---|---|
| AU | 1984 | 20 |
| CN | 1984 | 30 |
| USA | 1984 | 29 |
| AU | 1980 | 20 |
| CN | 1980 | 30 |
We can use a JOIN to lookup values in countries, or “bring over” the matching values from countries, so that each row that has “CN” has “China” in a new column, each row that has “AU” has “Australia” etc.
SELECT *
FROM olympic_medals
LEFT JOIN countries ON olympic_medals.country = countries.iso_code2Now we get:
| country | year_occured | medal_count | english_name | iso_code3 | iso_code2 |
|---|---|---|---|---|---|
| AU | 1984 | 20 | Australia | AU | AUS |
| CN | 1984 | 30 | China | CN | CHN |
| USA | 1984 | 29 | United States of America | US | USA |
| AU | 1980 | 20 | Australia | AU | AUS |
| CN | 1980 | 30 | China | CN | CHN |
You can see that using joins by default brings over all of the columns, but we can use SELECT to get just those we want, renaming using AS if we wish.
SELECT english_name AS country_name, year_occured, medal_count
FROM olympic_medals
LEFT JOIN countries ON olympic_medals.country = countries.iso_code2Note that I used a LEFT JOIN above. If I used just JOIN on its own I would get an inner join. In these particular data that would be the same, but if we had a two letter code in a row of the olympic_medals data that wasn’t in the lookup table then we would lose the row. That isn’t usually what we want, so LEFT JOIN protects against that.
Discuss:
- How would we find out if a row didn’t get matched up? What value would country_name show?
If someone is doing a “lookup” then they will almost always use a LEFT JOIN followed later in their workflow by dropping null values. That makes the dropping of data more explicit.
Using JOIN with foreign key columns
Recall our string database? When we converted that to tabular relational form, we used id and foreign_id columns (e.g., colors.id and objects.color_id) to represent the relationships between things. We had this structure:
objects
| id | name | color_id |
|---|---|---|
| 1 | Mug | 10 |
| 2 | Pen | 20 |
colors
| id | name |
|---|---|
| 10 | red |
| 20 | green |
We can use joins to lookup the color for each object. This is just like the case above, except instead of AU and CN we have the 10 and 20 labels in color_id.
SELECT *
FROM objects
JOIN colors ON objects.color_id = colors.id;results
| id | name | color_id | id | name |
|---|---|---|---|---|
| 1 | Mug | 10 | 10 | red |
| 2 | Pen | 20 | 20 | green |
Note that both objects and colors have a column name (and a column id). SQL allows this in results tables (duckdb differs from other SQL databases in that it renames them to name and name_2), but it is confusing so we usually use AS to rename things.
SELECT objects.name AS object_name,
colors.name AS color_name
FROM objects
JOIN colors ON objects.color_id = colors.id;| object_name | color_name |
|---|---|
| Mug | red |
| Pen | green |
This pattern of joining with an ON condition that matches up primary key and foreign key is very common; this is what we’ve done so far in this course. The id is used in other tables to represent a relationship with a row in a different table. This allows us to stitch back together data that is spread across databases.
You may notice that I’ve used JOIN (inner join) rather than LEFT JOIN (outer join) in this example. This is because when we have primary and foreign key columns we usually have “well-formed” data with “referential integrity” meaning that we don’t have “orphaned records” such that an id in a foreign key column will not be missing in the table it refers to. For example, we could add a new object, a purple pencil.
objects
| id | name | color_id |
|---|---|---|
| 1 | Mug | 10 |
| 2 | Pen | 20 |
| 3 | Pencil | 30 |
But if the colors table does not have a row for purple (30, purple) then beware that using just JOIN will silently drop our pencil.
You can watch out for this as you build up your sequence of queries, using -- sql comments to keep track of the number of rows.
SELECT *
FROM objects;
--> 3 rows
-- Now join to colors table to convert color_id to a color name.
SELECT *
FROM objects
JOIN colors ON objects.color_id = colors.id;
--> 2 rows?????????????????????????
-- Why did this drop to 2 rows?
SELECT *
FROM objects
LEFT JOIN colors ON objects.color_id = colors.id;
-- 3 rows. hmmm, the pencil doesn't have a color. Are we missing a color definition?Historically databases enforced “referential integrity” by marking foreign key columns with REFERENCING in the CREATE TABLE statement. This ensured that you could not insert a row with a “hanging” foreign key. If you tried the database would throw an error.
Today the fashion seems to be to avoid specifying these checks in the database itself. The argument for this approach is that these sort of checks are part of a wider set of validation requirements. For example, checking that a phone number matches a valid particular pattern, or a mailing address is valid, or an age is not negative. The tendency is to push validation outside the database, such as to javascript libraries (for data coming from web forms) or to test steps in data engineering toolchains.
In the data engineering and data warehouse world, this practice (of not specifying REFERENCES relationships in the table definitions) is reinforced in data engineering pipelines, because data is imported table by table, so there frequently are situations where foreign keys do not resolve, at least temporarily. The approach in data engineering is to import all data, then sort it out in the pipeline.
The takeaway here is that using LEFT JOIN when joining tables with primary and foreign keys is certainly a legitimate and important part of data validation and should probably be the default during data exploration.
The downside of using an outer join, though, is that all the records in the left table are retained. When working interactively doing data exploration, this can be problematic when the amount of data is large.
For example, you might be working with data like this in your projects. You might have a table with data for every city in the country … but you only have weather data for a few of them. In your project you probably want to drop data for which you don’t have matching data. So then you might just use JOIN rather than LEFT JOIN (which would leave you with lots of NULLs) That said, we will learn approaches to address this sort of thing on the way into the database, using Python.
Using AS in joins (table abbreviations)
As you can see above, joins can get long and the ON conditions in particular are often hard to fit on one line. They get even longer if one adds conditions in the WHERE clause.
We can provide abbreviations to tables to shorten queries. We do this with FROM table AS t
For example, FROM functions AS f and FROM objects AS o would shorten the query above somewhat:
SELECT o.name AS object_name,
c.name AS color_name,
f.name AS function_name
FROM objects AS o
JOIN colors AS c ON o.color_id = c.id
JOIN functions AS f ON o.function_id = f.idThis is useful, although the definition of the abbreviation comes in the middle of the query, after it has already been used.
Aliasing tables is common and you will find it very frequently when searching online. However, reasonable people can disagree about its usefulness.
Pros: - Queries are faster to type - Queries can be more compact, and compactness helps legibility especially when line wraps are avoided
Cons:
Abbreviations can be ambiguous. They are not always obvious, especially when tables start with the same letters. Does
prefer topeopleorpurchases? Different analysts might resolve this in different ways, or even the same analyst may use different abbreviations in different queries with different combinations of tables.It can harder to share queries with others, as abbreviations might not be standardized across groups.
“So
pis always people. Well, unlesspurchasesis also in the query, then I useppforpeopleandprfor purchases. But Katherine, I think, usespplor she used to. Oh, and if you join topeters_reporttry not to usepr? Got it?Column names can’t be abbreviated, so advantages are partial.
It can be hard to remember abbreviations when reading queries with many tables, especially if you haven’t worked with the data frequently.
Given that SQL is usually written with tab completion for table names, and colored syntax highlighting, table alisasing may not be as important. Although, given that we write little snippets of SQL everywhere (Slack channels, web Q&A, email) and compactness can help spot errors it will probably persist.
Notice the conventions used by those around you, ask what your team prefers.